Motivation of Word Representation
Unlike images data which have a long tradition of using vectors of pixels, natural language text has no unified representation for a long time. It was always regarded as discrete atomic symbol, where each word was asigned an unique id. Recent years, a popular idea in modern machine learning is to represent words by vectors.
Breif History of Word Representation
- Dictionary Lookup
- One Hot Encoding
- Word embedding (distributional semantic model)
- Distributed Word Representations
- word2vec
- Glove
- Contextural Word Representations
- CoVe
- ELMo
- BERT
Dictionary Lookup
The most straightforward way to represent a word is to create a dictionary and assign every word a unique ID. In languages like English, the form of the word changes depending on the context, and we can first apply the lemmatization.
One Hot Encoding
This method uses a vocabulary size vector to represent word. For a single word only corresponding column is filled with the value 1 and the rest are zero valued. The encoded tokens will consist of vector with dimension 1 × (N+ 1), where N is the size of the dictionary and the extra 1 is added to N for the Out of Vocabulary token.
Word Embedding
Word Embedding in NLP (or distributional semantic model in computational linguistics) comes from the idea: words that are used and occur in the same contexts tend to purport similar meanings. Distributional semantics favor the use of linear algebra as computational tool and representational framework. The basic approach is to collect distributional information in high-dimensional vectors, and to define distributional/semantic similarity in terms of vector similarity.
As semantic models, there are many different types: Latent Semantic Analysis/Indexing (LSA/LSI), Self Organizing Maps (SOM), Simple Recurrent Networks (SRN), Hyperspace Analogue to Language (HAL) …
Distributed Word Representations
word2vec
It is a word embedding toolkit which can train vector space models faster than the previous approaches created by a team in Google. It includes Skipgram and CBoW models, where are shallow networks. Word2vec is not technically not be considered a component of deep learning, with the reasoning being that its architecture is neither deep nor uses non-linearities. The embedding for a word \(w\) is trained to predict the words that co-occur with \(w\).
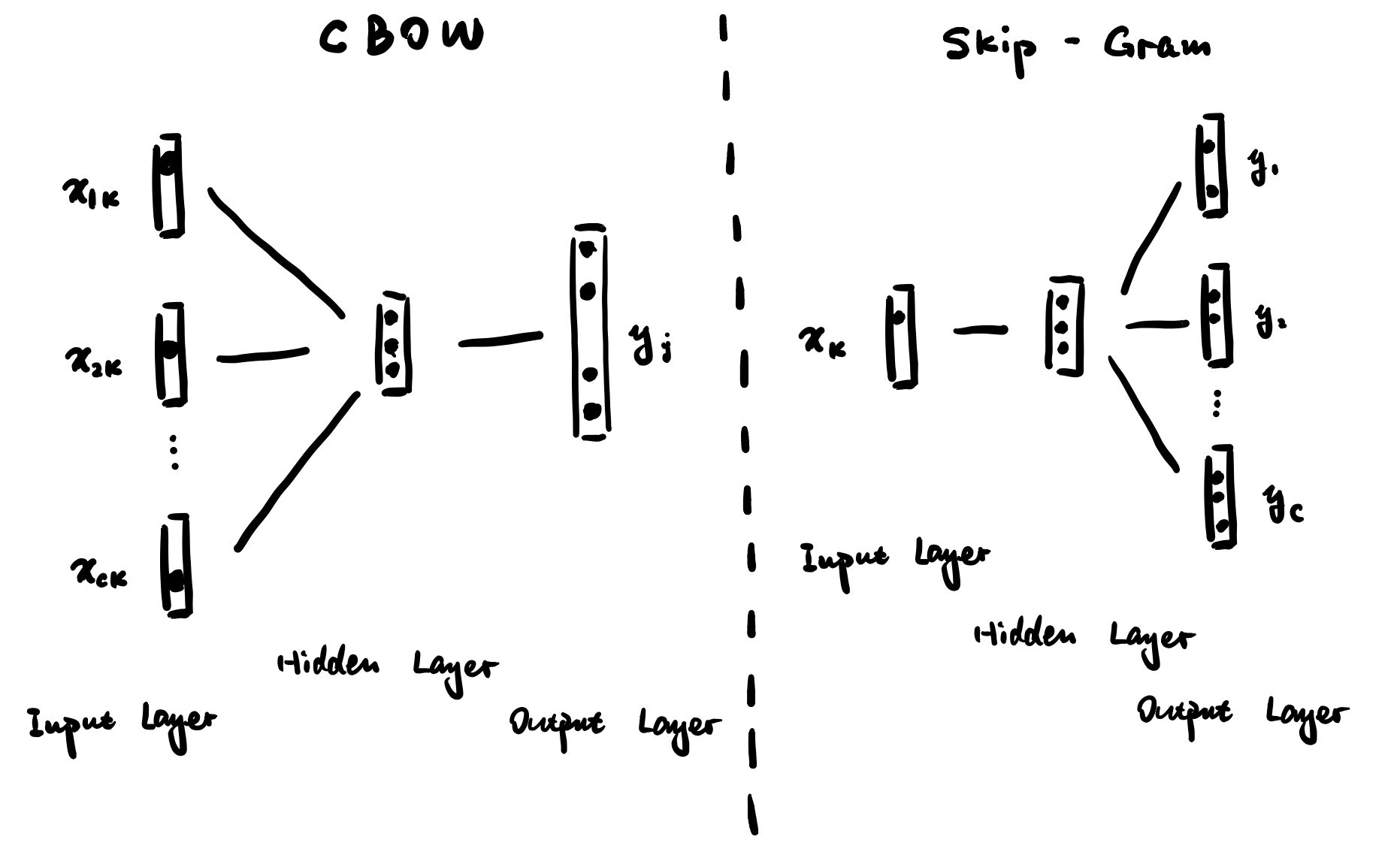
CBOW (Continuous Bag of Words Model): predict the center word given the surrounding context.
Skip-Gram: predicting surrounding context words given a center word.
Glove
The model tries to combine statistics of word occurrences in a corpus and skip-gram model. Glove makes explicit the model properties: encoding meaning as vector offsets in an embedding space.
Roughly speaking, the objective is to learn vectors for words \(w_{i}\) and \(w_{j}\) such that their dot product is proportional to their probability of co-occurrence:
$$w_{i}^{\top}\widetilde{w}_{k} + b_{i} + \widetilde{b}_{k} = \log(X_{ik})$$
The paper is exceptionally good at motivating this objective from first principles. In their equation (6), they define
$$w_{i}^{\top}\widetilde{w}_{k} = \log(P_{ik}) = \log(X_{ik}) - \log(X_{i})$$
If we allow that the rows and columns can be different, then we would do
$$w_{i}^{\top}\widetilde{w}_{k} = \log(P_{ik}) = \log(X_{ik}) - \log(X_{i} \cdot X_{*k})$$
where, as in the paper, \(X_{i}\) is the sum of the values in row \(i\), and \(X_{*k}\) is the sum of the values in column \(k\).
The rightmost expression is PMI by the equivalence \(\log(\frac{x}{y}) = \log(x) - \log(y)\), and hence we can see GloVe as aiming to make the dot product of two learned vectors equal to the PMI!
The full model is a weighting of this objective:
$$\sum_{i, j=1}^{|V|} f\left(X_{ij}\right) \left(w_i^\top \widetilde{w}_j + b_i + \widetilde{b}_j - \log X_{ij}\right)^2$$
where \(V\) is the vocabulary and \(f\) is a scaling factor designed to diminish the impact of very large co-occurrence counts:
$$f(x)
\begin{cases}
(x/x_{\max})^{\alpha} & \textrm{if } x < x_{\max}
1 & \textrm{otherwise}
\end{cases}$$
Typically, \(\alpha\) is set to \(0.75\) and \(x_{\max}\) to \(100\)
Contextural Word Representations
CoVe
CoVe computes contextualized representations using a neural machine translation encoder.
ELMo
This model tries to work on the challenges (1) complex characteristics of word use (e.g., syntax and semantics), (2) how these uses vary across linguistic contexts. It generates embeddings for a word based on the context it appears thus generating slightly different embeddings for each of its occurrence. The model is trained with Bidirectional Language Model in the unsupervised way.
- character convolution
- two layer biLMs (forward + backword)
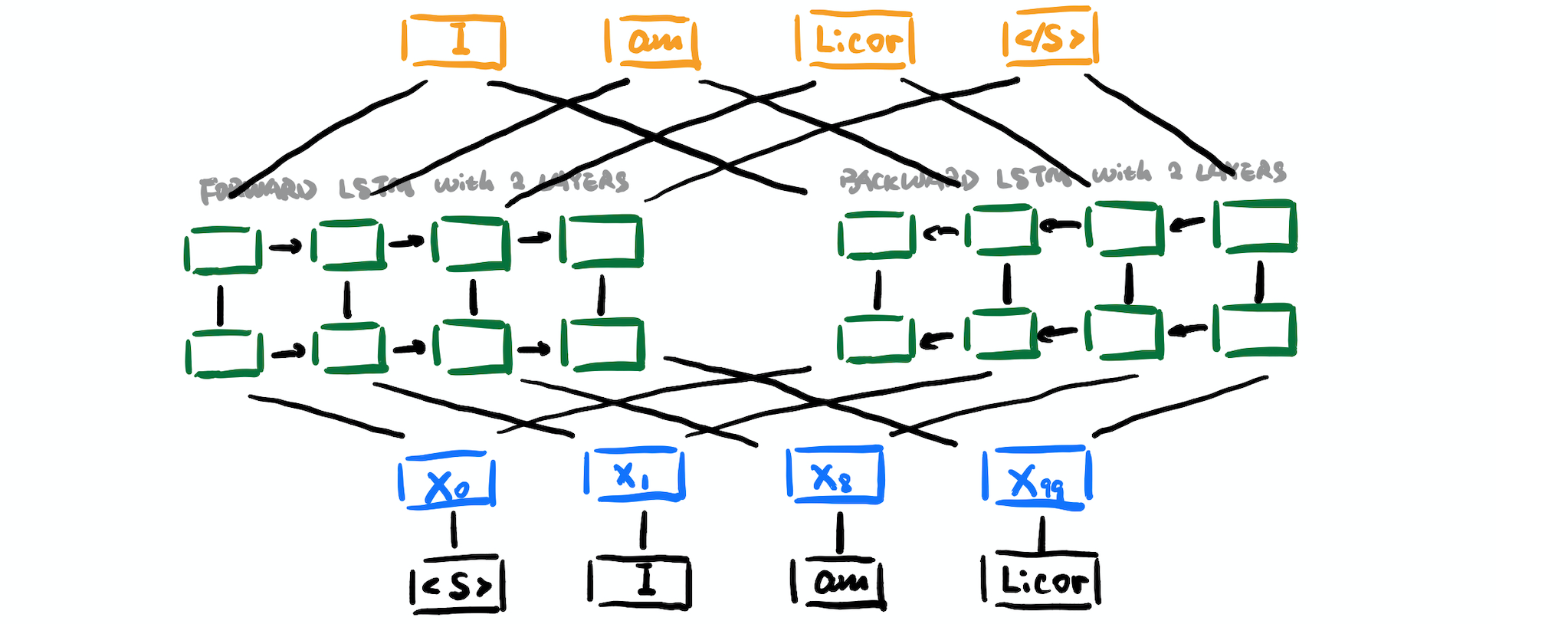
X is the token representation(via token embeddings or a CNN over characters)
Bert
Bert uses attention transformers instead of bi-directonal RNNs to encode context. The model learns to predict both context on the left and right.
- Transformer
- Position Embedding + Segment Embedding + Token Embedding
- Masked token prediction
Reference
Word Representation in Natural Language Processing Part I
A brief history of word embeddings (and some clarifications)
Distributional semantics - Wikipedia
Word embedding - Wikipedia
An overview of word embeddings and their connection to distributional semantic models
How is GloVe different from word2vec?
Beyond Word Embeddings Part 2
Learning Word Embedding
Distributed Representations of Words and Phrases and their Compositionality
GloVe: Global Vectors for Word Representation
Deep contextualized word representations
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
CS224U