Transformer was introduced in Attention Is All You Need in 2017. It’s a neural network architecture based on a self-attention mechanism and has proved its excellent performance in language understanding.
Background
- Typical recurrent models suffer from a large amount of computation
- Critical information in long sequences is difficult to represent in RNNs
- Attention mechanisms are effective
A quick recap of attention
Given a sequence to sequence model:
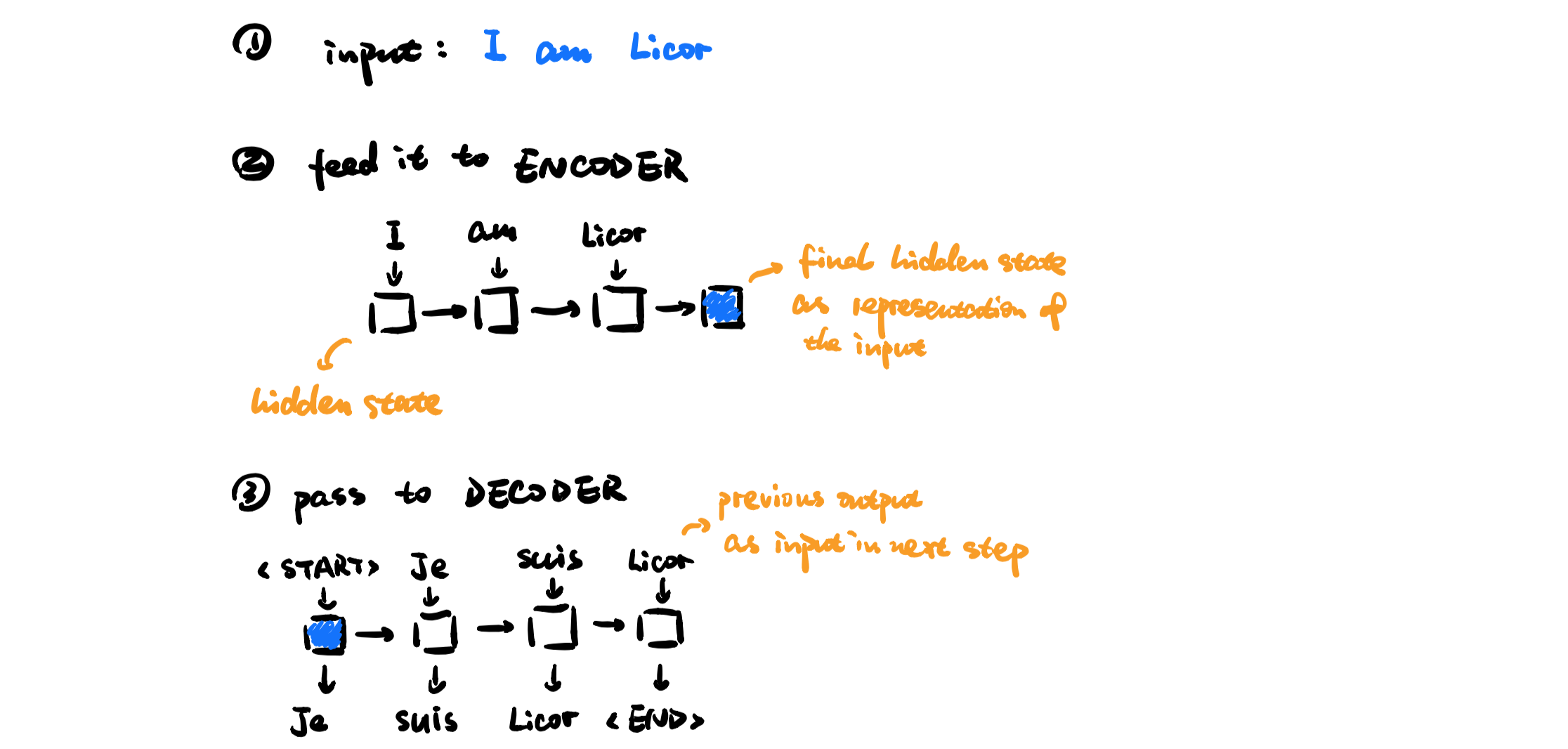
We can calculate attention score in this way:

General definition of attention
Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values, dependent on the query.
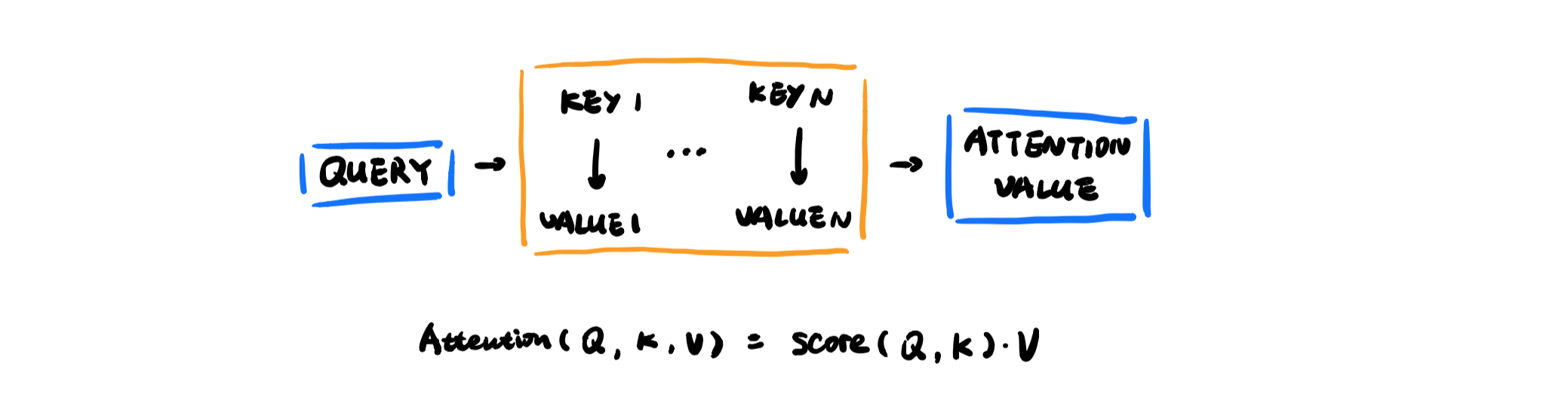
In the previous example, query is the hidden state in decoder \(s_t \), there is no separation of key and value, they are encoder hidden states \(h_1, h_2, …, h_N \).
Scaled Dot-Product Attention
Every word in the input sequence has three corresponding vectors. When we have multiple vectors, we stack them in a matrix.
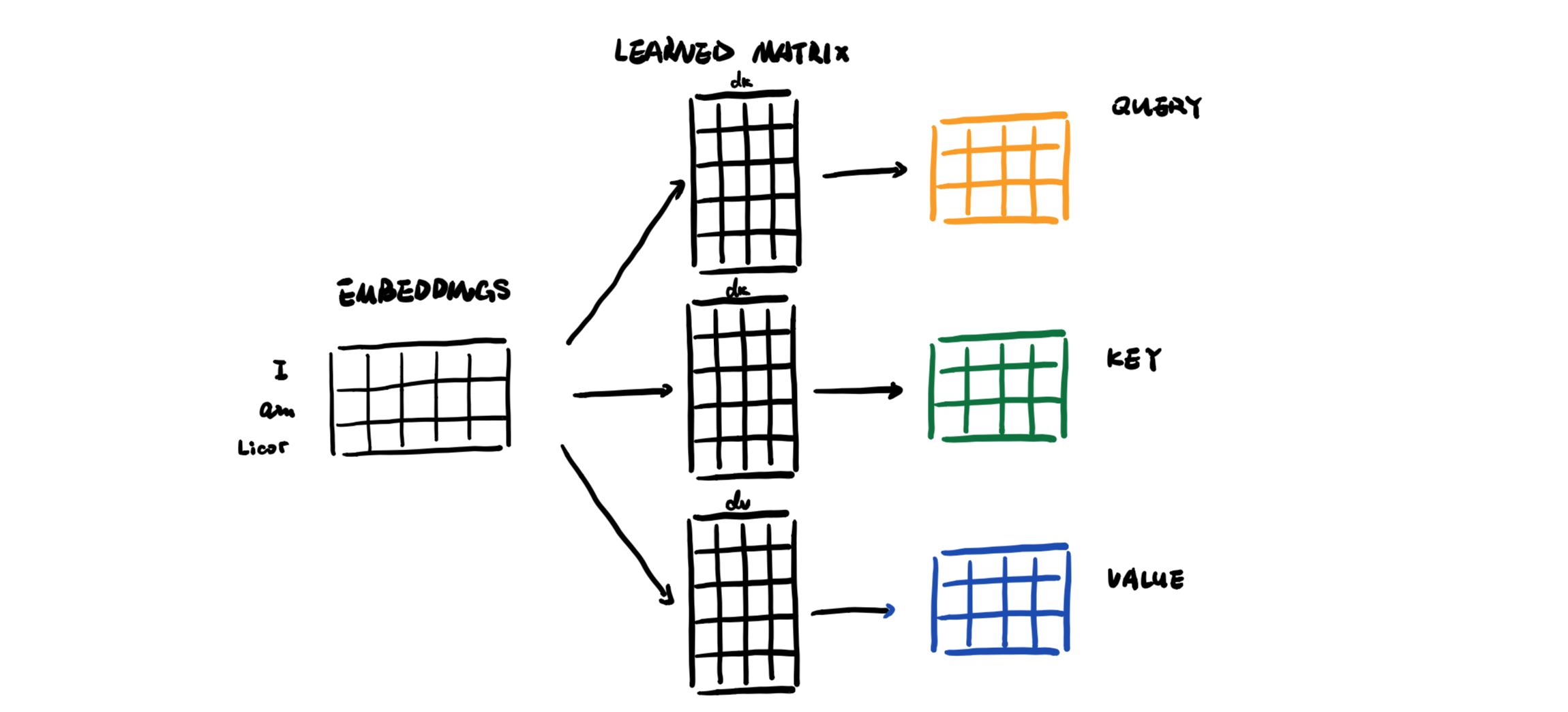
And we can calculate attention with the three matrixs:
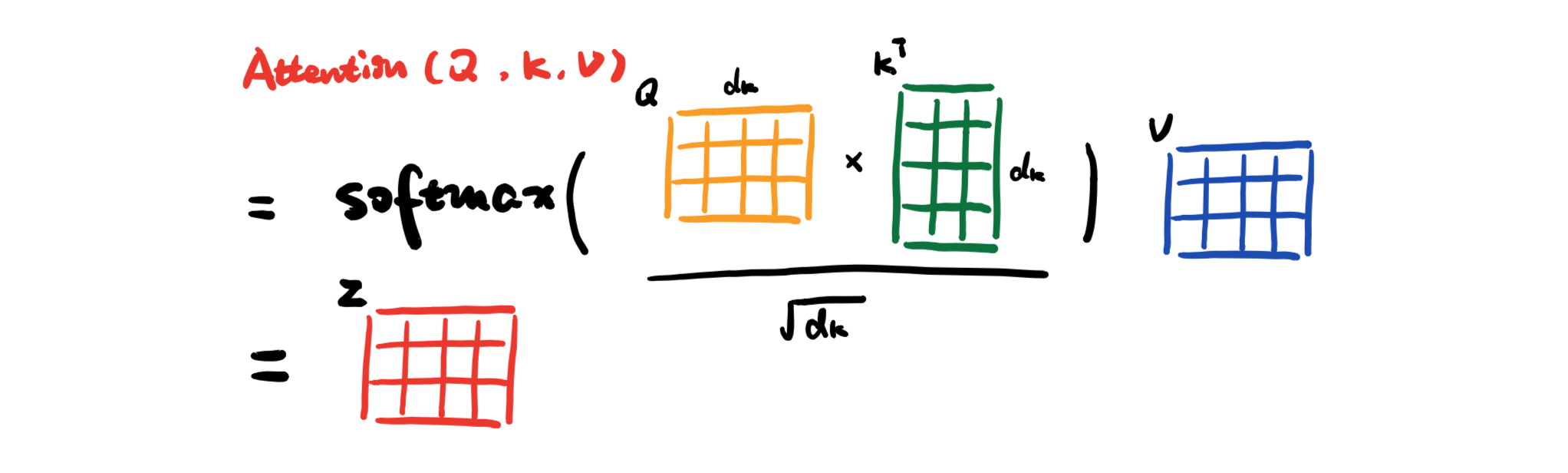
As \(d_k \) gets large, the variance of \(Q^{T}K\) increases, some values inside the softmax get large, so the softmax gets very peaked, hence its gradient gets smaller. As a solution, the attention value is scale by the length of query/key vectors.
Multi-Head Attention
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
To make it more explict, scaled dot-product attention can be considered as way for words to make connection with each other,
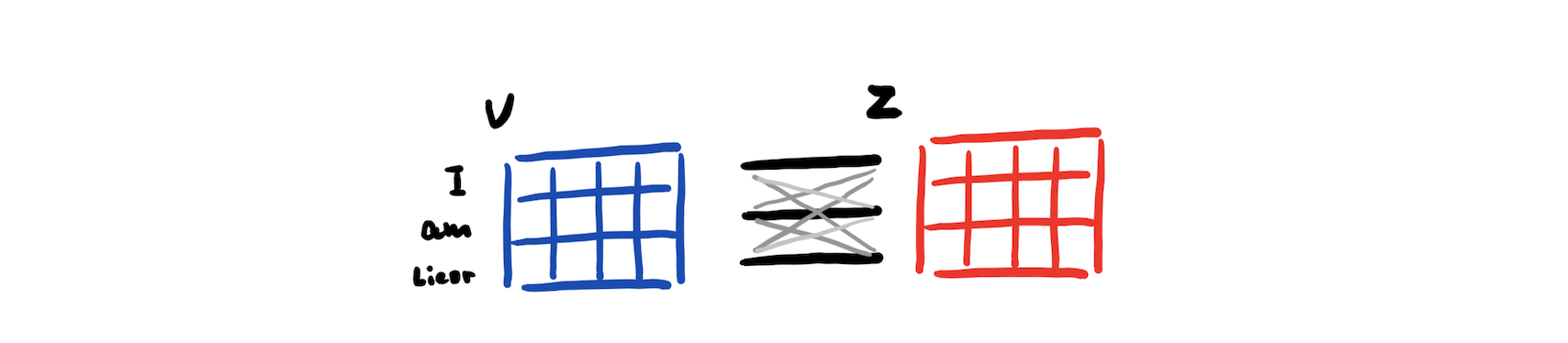 but the problem is that it’s only one way for words to interact with one another.
but the problem is that it’s only one way for words to interact with one another.
So to let words make more interactions, we can map \(Q, K, V\) into many lower dimensional spaces and concatenate all the outputs.
Make linear projection:
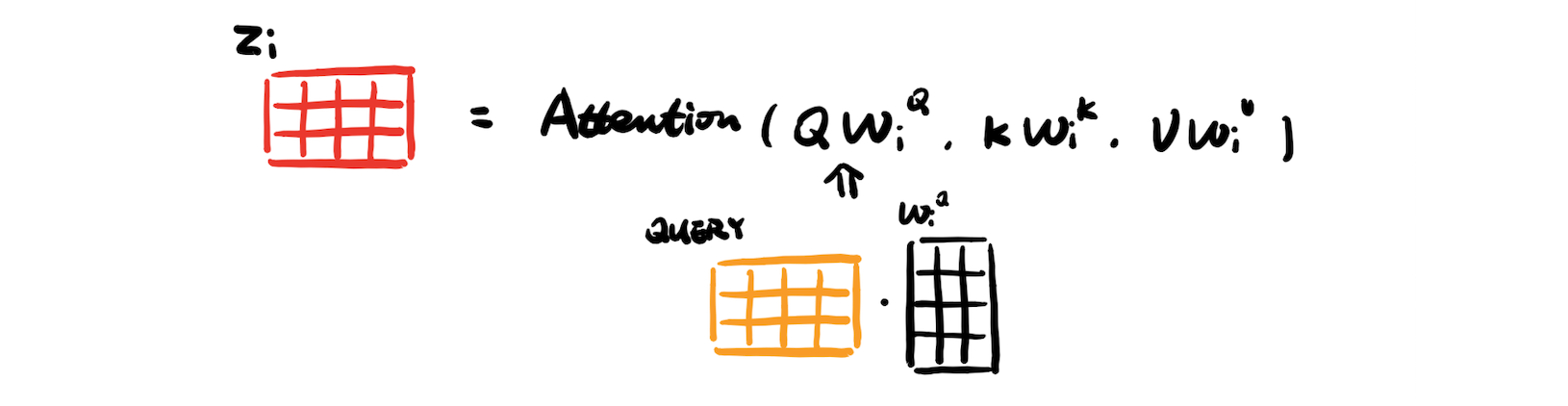
Concatenate all the outputs:
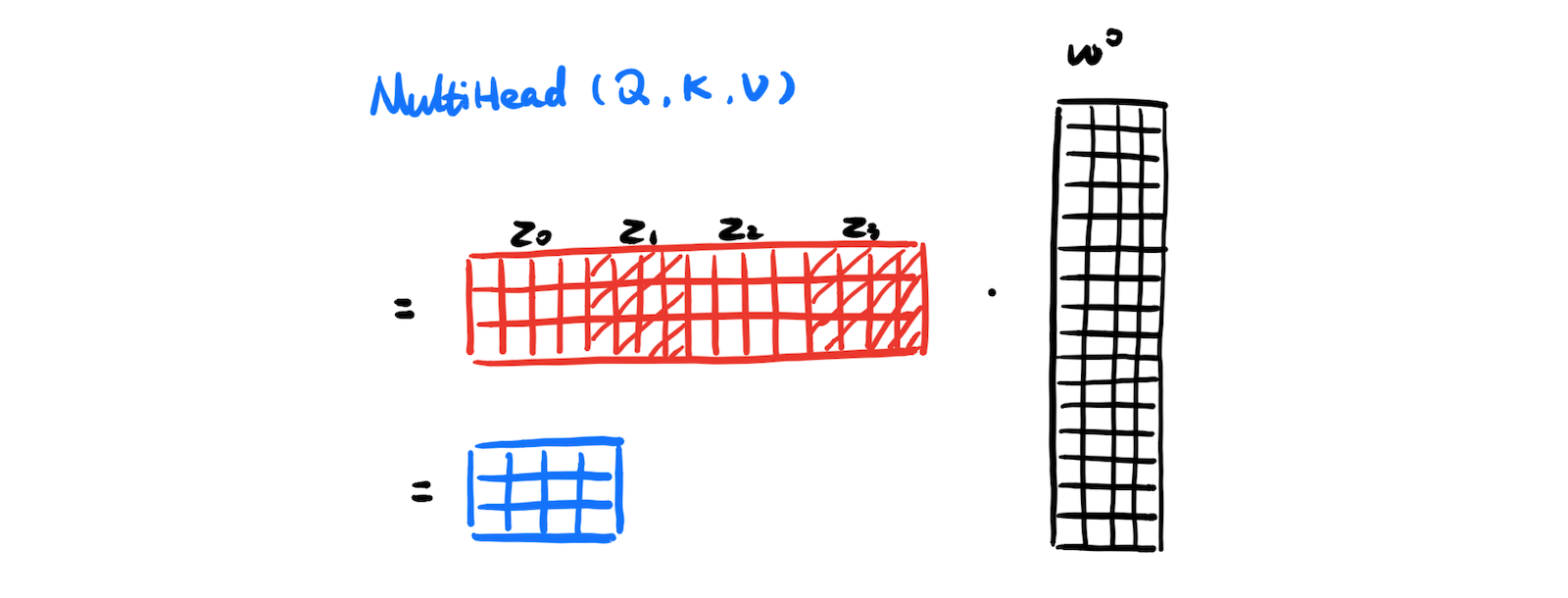
Rest of the block
Feed-Forward Networks
Every attention sub-layers contains a fully connected feed-forward network, and this consists of two linear transformations with a ReLU activation in betweenResidual Connection
It’s clear in the model architecture that there’s residual connection around each of the two sub-layers in the blockLayer Normalization
The output of each sub-layer is applied with layer normalization function, transformed to have mean 0 and variance 1
Positional Encoding
Until now, words in a sequence are treated the same way, the representations of words are indifferent to their positions. To take this critical feature into consideration, add positional encodings to the input embeddings at the bottoms of the encoder and decoder stacks.
$$PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}})$$ $$PE_{(pos,2i+1)} = cos(pos/10000^{2i/d{model}})$$ where \(pos\) is the position and \(i\) is the dimension.