First introduced in computer vision, visual attention explained the perception towards the world of creatures in some way. I remember the first time I met attention was reading the paper Show and tell: A neural image caption generator during doing work related to image captioning. And in the area of NLP, tasks like machine translation, speech recognition, attention really makes a difference, it was started by combining with Seq2Seq model, then new model like Transformer tried to getting out of this.
So, what is attention
Attention is simply a vector, often the outputs of dense layer using softmax function. It computes a weighted sum of the values, dependent on the query. In Seq2Seq, it is useful to allow decoder to focus on certain parts of the source and provides short cut to faraway states, thus help with vanishing gradient problem.
And what really is attention
Here is a simple example of sequence to sequence model:
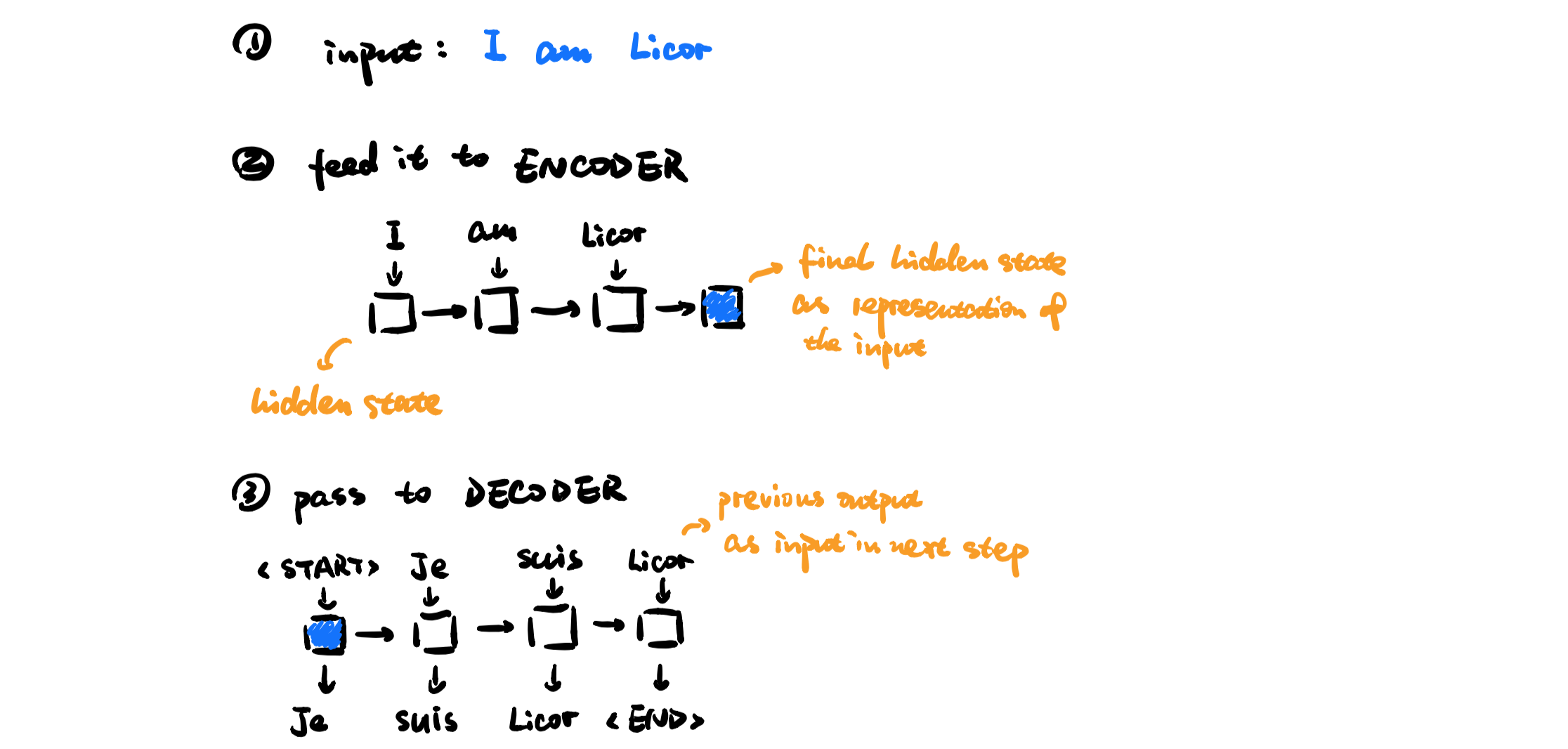
Starting from Seq2Seq, we can compute the basic attention distribution in this way:

Given encoder hidden state \(h_1, h_2, …, h_N \in \mathbb{R}^{h}\) On time step \(t \), the decoder hidden state \(s_t \in \mathbb{R}^{h} \)
Get the attention scores \(e^{t}\) for this time step: $$e^{t} = [s_t^{T}h_1, …, s_t^{T}h_N] \in \mathbb{R}^{N}$$
Then take the softmax to get the distribution: $$\alpha^{t} = softmax(e^{t}) \in \mathbb{R}^{N}$$
The attention output is: $$a_t = \sum_{i=1}^{N} \alpha_i^{t}h_i \in \mathbb{R}^{h}$$
Finally concatenate the attention output with the decoder hidden state: $$[a_t;s_t] \in \mathbb{R}^{2h}$$
Voilà! Then the hidden state with the attention output is process as before.
Attention techniques
Besides Seq2Seq with basic attention, there’s other model to explore this area. Google Brain team identified the following four techniques for building attention into RNNs models:
Neural Turing Machines
NTM introdeced a RNN with external memory bank which powerd by attention distribution. The memory is an array of vectors.
Attentional Interfaces
Attentional interfaces uses an RNN model to focus on specific sections of another neural network. The attention distribution is usually generated with content-based attention.
Adaptive Computation Time
Adaptive computation time techniques used an attention distribution model to the number of steps to run each time allowing to put more emphasis on specific parts of the model. Standard RNNs do the same amount of computation for each time step. Use attention distribution to determine number of steps to run.
Neural Programmer
Neural programmer models focus on learning to create programs in order to solve a specific task.
Reference
A Brief Overview of Attention Mechanism
CS224n
Attention and Augmented Recurrent Neural Networks
What’s New in Deep Learning Research: About Attentional Interfaces