Types of questions
- Factoid questions
How many calories are there in two slices of apple pie?
Most question answering systems focus on factoid questions, that can be answered with simple facts expressed in short texts. The answers to the questions usually can be expressed by a personal name, temporal expression, or location.
- Complex (narrative) questions:
In children with an acute febrile illness, what is the efficacy of acetaminophen in reducing fever?
Paradigms for Question Answering
Information Retrieval-based and Knowledge-based approaches, and we could make them to a hybrid approach. Large industrial systems use hybrid approaches, they find many candidate answers in both knowledge bases and in textual sources, and then scores each candidate answer using knowledge sources like geospatial databases, taxonomical classification, or other textual sources.
Information Retrieval-based Approach
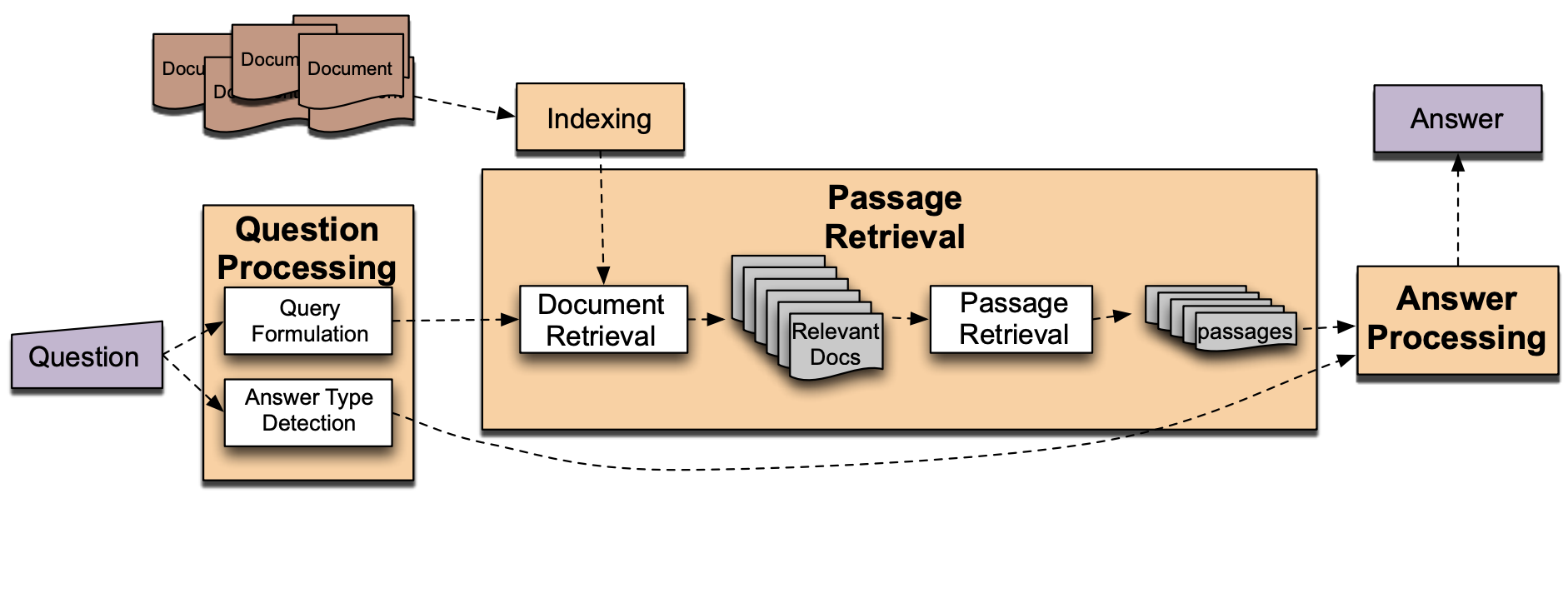
IR-based factoid question answering has three stages: question processing, passage retrieval, and answer processing.
Question Processing
The first step is to extract the query. Usually the keywords are extracted, and sometimes further information such as answer type (the entity type), focus (words tend to be replaced by the answer), question type (definition question, a math question, a list question), relations (between entities in the question).
| Question | Which US state capital has the largest population? |
| Answer type | city |
| Query | US state capital, largest, population |
| Focus | state capital |
Answer type detection
Generally it’s a classification task based on supervised learning methods or hand-written rules. Answer types (class labels) can be built automatically from resources like WordNet or designed by hand like Answer Type Taxonomy(from Li & Roth).
Features including:
- words in the questions
- part-of-speech of each word
- named entities in the questions
- answer type word(question headword): a single word in the question gives extra information about the answer type and may be defined as the headword of the first NP after the question’s wh-word.
- semantic information about the words in the questions like WordNet synset ID of the word
Query Formulation
Formulate queries to send to a search engine. For question answering from the web, we can simply pass the entire question to the web search engine. For question answering from smaller sets of documents like corporate information pages or Wikipedia, we might need to do more processing like query expansion and query reformulation.
Query expansion adds morphological variants of the content words in the question, or synonyms from a thesaurus.
Query reformulation applies rules to a query. e.g. Where is A -> A is located in
Keyword selection:
- Select all non-stop words in quotations
- Select all NNP words in recognized named entities
- Select all complex nominals with their adjectival modifiers
- Select all other complex nominals
- Select all nouns with their adjectival modifiers
- Select all other nouns
- Select all verbs
- Select all adverbs
- Select the QFW word (skipped in all previous steps)
- Select all other words
Passage Retrieval
This step results in a set of documents ranked by their relevance to the query. And then segment the documents into shorter units.
The simplest form of passage retrieval is then to simply pass along every passage to the answer extraction stage. A more sophisticated variant is to filter the passages by running a named entity or answer type classification on the retrieved passages, discarding passages that don’t contain the answer type of the question. This rank can be finished by supervised learning using features like:
- The number of named entities of the right type in the passage
- The number of question keywords in the passage
- The longest exact sequence of question keywords that occurs in the passage
- The rank of the document from which the passage was extracted
- The proximity of the keywords from the original query to each other
- The number of n-grams that overlap between the passage and the question
Answer Processing
The final stage of question answering is to extract a specific answer from the passage.
Pattern Extraction
Run an answer-type named-entity tagger on the passages and return the string with the right type.
e.g. How tall is Mt. Everest? (LENGTH)
The official height of Mount Everest is 29035 feet
Feature-based Answer Extraction
If there’re multiple named entity candidates or answer type is not specific, we need to do more. And again we can use supervised learning approaches to train classifiers to find the answer.
Features can be used to train classifiers including:
- Answer type match: True if the candidate answer contains a phrase with the correct answer type.
- Pattern match: The identity of a pattern that matches the candidate answer. Number of matched question keywords: How many question keywords are contained in the candidate answer.
- Keyword distance: The distance between the candidate answer and query keywords.
- Novelty factor: True if at least one word in the candidate answer is novel, that is, not in the query.
- Apposition features: True if the candidate answer is an appositive to a phrase containing many question terms.
- Punctuation location: True if the candidate answer is immediately followed by a comma, period, quotation marks, semicolon, or exclamation mark.
- Sequences of question terms: The length of the longest sequence of question terms that occurs in the candidate answer.
N-gram tiling Answer Extraction
- N-gram mining extract and weight every unigram, bigram, and trigram occurring in the snippet
- N-gram filtering n-grams are scored by how well they match the predicted answer type
- n-gram tiling concatenate overlapping n-gram fragments into longer answers
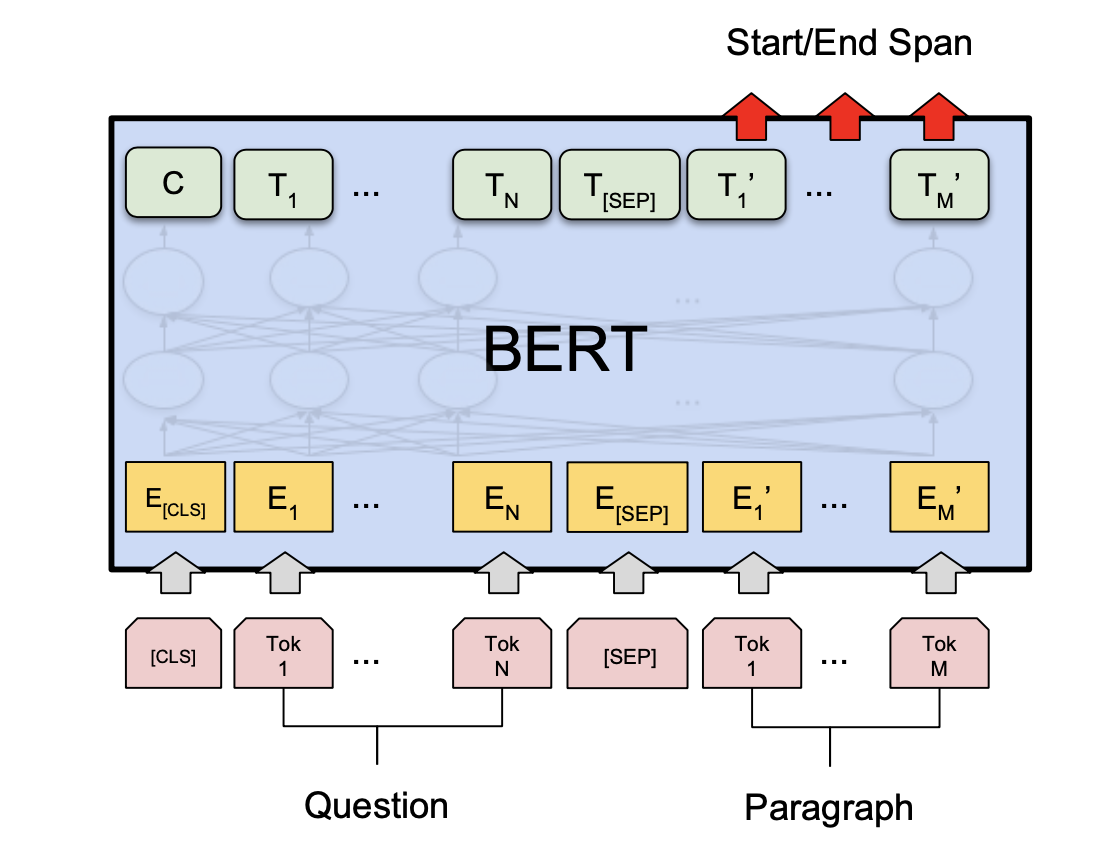
Neural Answer Extraction
Take reading comprehension datasets like SQuAD and fine-tune on BERT is a general approach nowadays.
Knowledge-based Approach
For information in structured forms, we can answer a natural language question by mapping it to a query over a structured database. Systems for mapping from a text string to any logical form are called semantic parsers.
| Question | Logical form |
|---|---|
| When was Ada Lovelace born? | birth-year (Ada Lovelace, ?x) |
| What states border Texas? | λ x.state(x) ∧ borders(x,texas) argmax(λx.state(x),λx.size(x)) |
| What is the largest state How many people survived the sinking of the Titanic | (count (!fb:event.disaster.survivors fb:en.sinking of the titanic)) |
The database can be a full relational database, or simpler structured databases like sets of RDF triples. The simplest formation of the knowledge-based question answering task is to answer factoid questions that ask about one of the missing arguments in a triple.
| |subject | predicate | object |
|---|---|---|
| England | capital-city | London |
“What is the capital of England?” -> capital-city(?x, England)
Rule-based Methods
For very frequent relations, it may be worthwhile to write handwritten rules to extract relations from the question.
Supervised Methods
Most supervised algorithms for learning to answer these simple questions about relations first parse the questions and then align the parse trees to the logical form.
Generally these systems bootstrap by a small set of rules for building this mapping, and an initial lexicon:

Then training instances like following would be parsed like following:

A supervised system would thus parse each tuple in the training set and induce a bigger set of such specific rules, allowing it to map unseen examples of “When was X born?” questions to the birth-year relation.
Semi-Supervised Methods
It is difficult to create training sets with questions labeled with their meaning representation, supervised datasets can’t cover the wide variety of forms that even simple factoid questions can take. To use the web as source of textual variants, most methods use semi-supervised methods like distant supervision or unsupervised methods like open information extraction.
We can create new relations by aligning relations in triple form with web data. For example, we match web content with fist and last elements in ("Ada Lovelace","was born in", "1815"), we can get many variants of phrases with the meaning “was born in”
Paraphrase databases are useful redundancy sources. Those paraphrases can be aligned to each other using MT alignment approaches to create an MT-style phrase table for translating from question phrases to synonymous phrases. These can be used by question answering algorithms to generate all paraphrases of a question as part of the process of finding an answer.
Hybrid Approach
This is the architecture of IBM Waston.
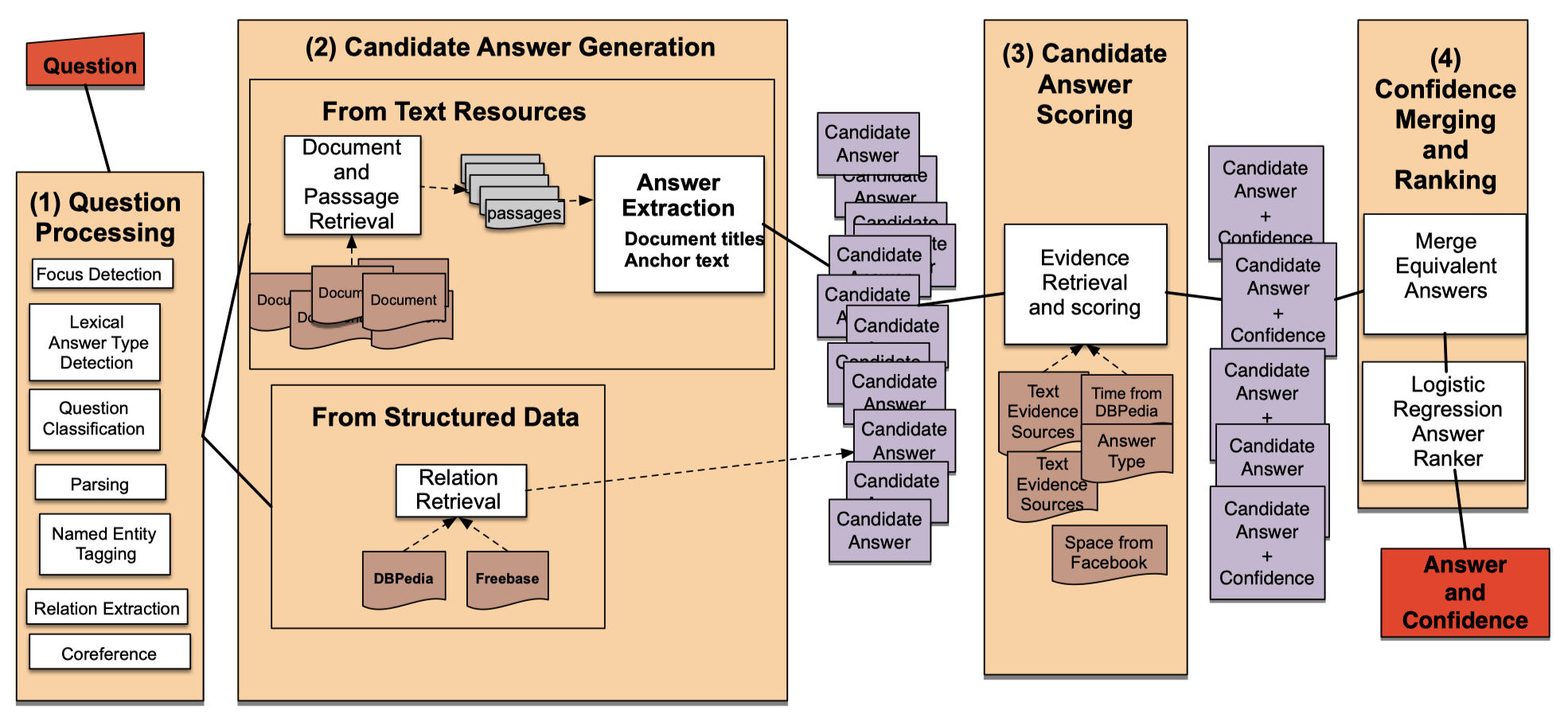
There’re four broad stages of Waston.
The first stage is question processing, it runs parsing, named entity tagging, and relation extraction on the question. Then, the system extracts the focus, the answer type (also called the lexical answer type or LAT), and performs question classification and question sectioning.
In the second candidate answer generation stage, it suggests candidate answers either be extracted from text documents or from structured knowledge bases.
The third candidate answer scoring stage uses many sources of evidence to score the candidates. One of the most important is the lexical answer type.
The final answer merging and ranking step first merges candidate answers that are equivalent. Then a classifier takes each candidate’s feature vector and assigns a confidence value to this candidate answer. The classifier is trained on datasets of hand-labeled correct and incorrect answers.
Evaluation
MRR(mean reciprocal rank) is the most common evaluation metric for factoid question answering.
$$MRR = \frac{1}{N} \sum_{i=1}^{N} \frac{1}{rank_i}$$
MRR assumes a test set of questions that have been human-labeled with correct answers and systems are returning a short ranked list of answers or passages containing answers. Each question is scored according to the reciprocal of the rank of the first correct answer.
Reading comprehension systems on datasets like SQuAD are often evaluated using exact match and F1 score.