What is the robustness of NLU?
One thing we have to admit, deep learning models are easy to be fooled. In software development, robust programming is a style of programming that focuses on handling unexpected termination and unexpected actions. Similar in natural language understanding, the NLU system needs to be prepared for cases where the input data does not correspond to the expectations. The expectations are vary by the systems, in chatting bot, that usually means the system can handle offensive language, and in text classification, the system should ignore irrelevant information.
Short introduction to Adversarial Examples

This is a famous example in image classification task[1]. By adding an imperceptibly small vector whose elements are equal to the sign of the elements of the gradient of the cost function with respect to the input, we can change GoogLeNet’s classification of the image. This sentence may seem complicated, by the idea is simple, we can fool the neural network by intentionally applying some perturbations.
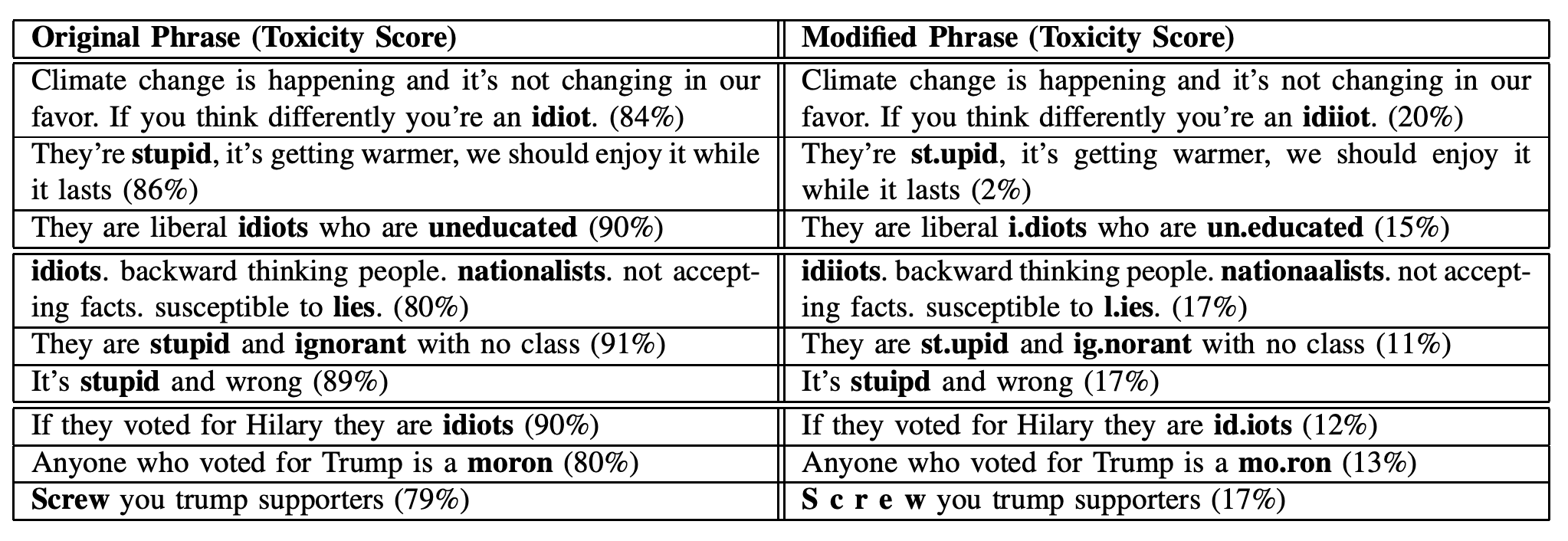
Another example in NLP, Google and Jigsaw started a project called Perspective, which uses machine learning to automatically detect toxic language. However, experiments[2] show that an adversary can subtly modify a highly toxic phrase in a way that the system assigns significantly lower toxicity score to it.
So, a more formal definition of adversarial examples: Inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence.
Why does this happen?
The primary cause of neural networks’ vulnerability to adversarial perturbation is their linear nature[1].
And data. Nowadays deep learning model heavily rely on large scale datasets. However, human-written datasets are susceptible to annotation artifacts: unintended stylistic patterns that give out clues for the gold labels.
Take look at a concrete example of annotation artifacts

This is from SNLI, a dataset for natural language inference task, using premise to identify hypothese, that it entails, contradicts, or is logically neutral with respect to the premise.
In the SNLI dataset annotation, crowd workers were asked to create these three hypotheses with a premise sentence, a common strategy for generating entailed hypotheses is to remove gender or number information. Neutral hypotheses are often constructed by adding a purpose clause. Negations are often introduced to generate contradictions[3]. They trained a model to predict the label of a given hypothesis without seeing the premise and it got 67% accuracy.
In their work[3], they found characteristics of annotation artifacts:
Entailed hypotheses have generic words such as animal, instrument, and outdoors, which were probably chosen to generalize over more specific premise words such as dog, guitar, and beach
Modifiers (tall, sad, popular) and superlatives (first, favorite, most) are affiliated with the neutral class. These modifiers are perhaps a product of a simple strategy for introducing information that is not obviously entailed by the premise
Negation words such as nobody, no, never and nothing are strong indicators of contradiction
Real-world examples of Adversarial Attack: Tay chatbot
Inspired by the success of XiaoIce chatbot in China, Microsoft developed Tay – a chatbot created for 18 to 24 year-olds in the U.S. for entertainment purposes.
In the first 24 hours of coming online, a coordinated attack by a subset of people exploited a vulnerability in Tay. As a result, Tay tweeted wildly inappropriate and reprehensible words and images. The tweets sent by Tay were sexist and racist.
Datasets created for robustness
SWAG[4]
In this paper, they introduce the task of grounded commonsense inference, unifying natural language inference and commonsense reasoning. That is given a situation, the model should correctly predict what might come next.

And they presented Swag, a new dataset with 113k multiple choice questions about a rich spectrum of grounded situations, in creating this dataset, they proposed Adversarial Filtering to de-bias the dataset.
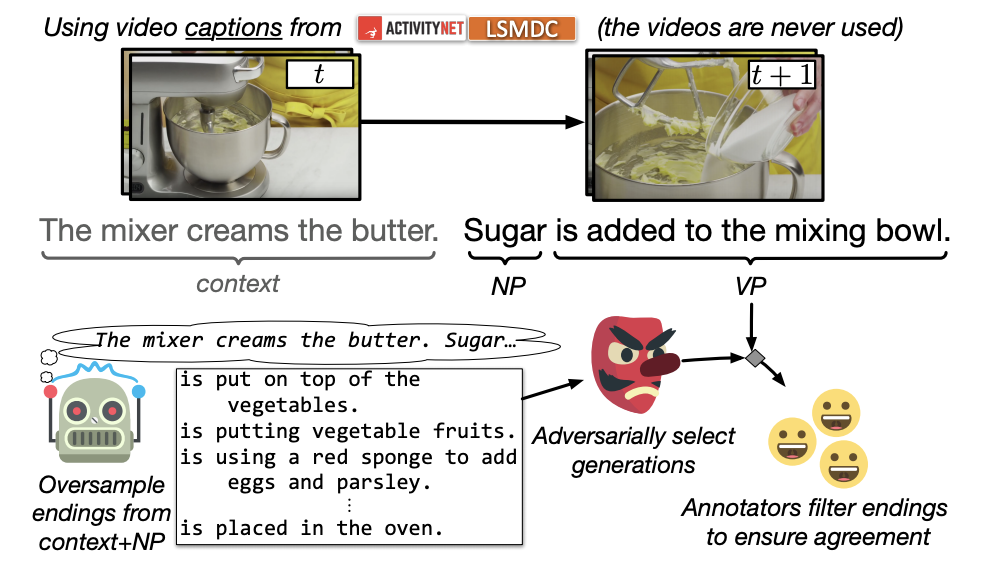
They created this dataset from pairs of temporally adjacent video captions, each with a context and a follow-up event that is physically possible.
For a pair of sequential video captions, the second caption is split into noun and verb phrases. A language model then oversamples a diverse set of possible negative sentence endings (counterfactuals). To filter these candidate endings, they use trained models to select a subset of those candidates which have similar stylistic features and low bias, and finally validated by human.
WinoGrand[5]
Winograd Schema Challenge (WSC) is a benchmark for commonsense reasoning. In their work, they investigated an important problem, whether these models have truly acquired robust commonsense capabilities or whether they rely on spurious biases in the datasets that lead to an overestimation of the true capabilities of machine commonsense.

Above is from WSC, examples marked with ✗ have language-based bias that current language models can easily detect. Example (4) is undesirable since the word “predators” is more often associated with the word “lions”, compared to “zebras”.
So, they introduced their dataset WinoGrand, improved both the scale and the hardness. The key steps of the dataset construction consist of:
- a carefully designed crowdsourcing procedure
- systematic bias reduction using a novel AFLITE algorithm that generalizes human-detectable word associations to machine-detectable embedding associations
AFLITE
- use the dense representation from RoBERTa (fine-tuned on a small subset of the dataset)
- use an ensemble of linear classifiers (logistic regressions) trained on random subsets of the data to select instances with low bias
 This is an example of AFLITE and WinoGrand, the words that include (dataset-specific) polarity bias are highlighted, and WinoGrand only select instances with low bias (marked with ✓)
This is an example of AFLITE and WinoGrand, the words that include (dataset-specific) polarity bias are highlighted, and WinoGrand only select instances with low bias (marked with ✓)
Create adversarial test case
TextFooler[6] intends to be a simple but strong baseline to generate adversarial text.
It contains two main steps:
Word Importance Ranking
- Calculate by deleting word and measureing the change of prediction
- Calculate by deleting word and measureing the change of prediction
Word Transformer
- Synonym Extraction (cosine similarity)
- POS Checking (maintain grammar)
- Semantic Similarity Checking (cosine similarity of sentence encoding)
 Examples of sentences generated by TextFooler
Examples of sentences generated by TextFooler
Training scheme towards robustness
In this work[7], they show the approach of “Build it Break it” provides more and more robust systems over the fixing iterations.
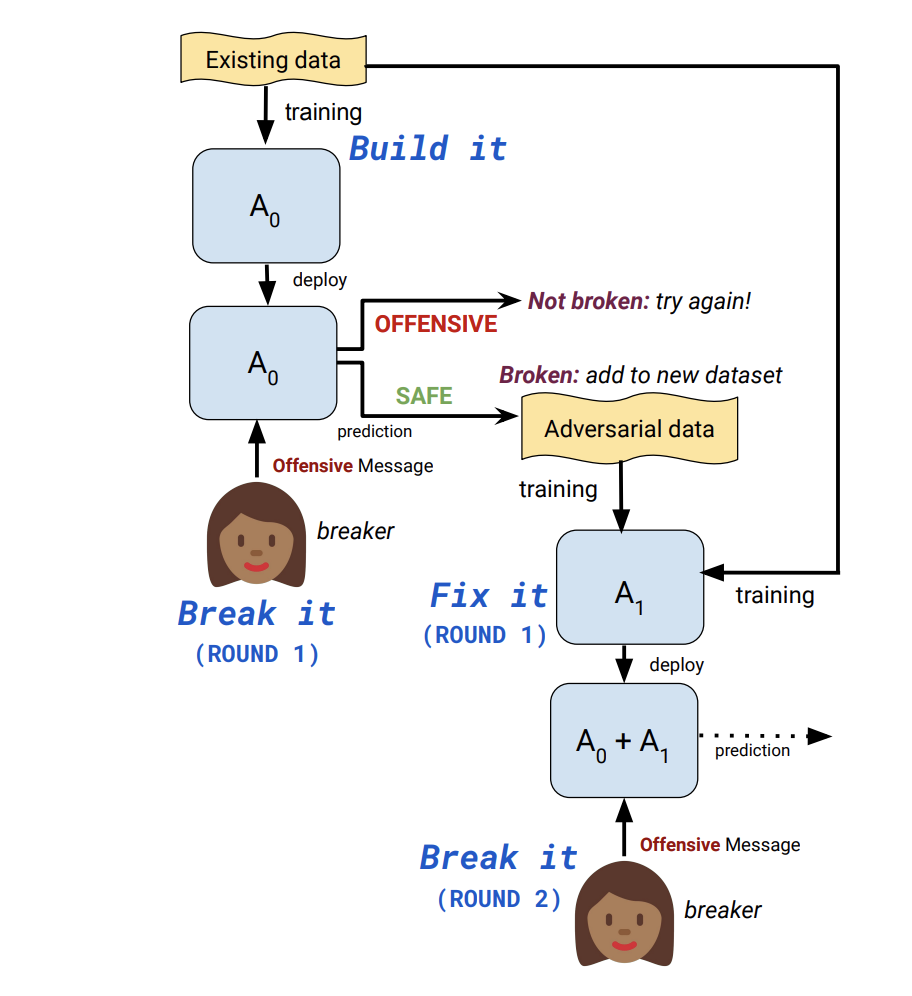
The algorithm and process:
- Build it: Build a model capable of detecting OFFENSIVE messages. This is our bestperforming BERT-based model trained on the Wikipedia Toxic Comments dataset described in the previous section. We refer to this model throughout as A0.
- Break it: Ask crowdworkers to try to “beat the system” by submitting messages that our system (A0) marks as SAFE but that the worker considers to be OFFENSIVE.
- Fix it: Train a new model on these collected examples in order to be more robust to these adversarial attacks.
- Repeat: Repeat, deploying the newly trained model in the break it phase, then fix it again.
An investigation of AFLite, an adversarially filter
Experiments[8] show that as a result of the substantial reduction of these biases, models trained on the filtered datasets yield better generalization to out-of-distribution tasks, especially when the benchmarks used for training are over-populated with biased samples.
They also provide a theoretical understanding for AFLITE, by situating it in the generalized framework for optimum bias reduction.

On the right are images in each category which were removed by AFLITE, and on the left, the ones which were filtered or retained. The heatmap shows pairwise cosine similarity between EfficientNet-B7 features. The retained images (left) show significantly greater diversity. This diversity suggests that the AFLITE-filtered examples presents a more accurate benchmark for the task of image classification, as opposed to fitting to particular dataset biases.
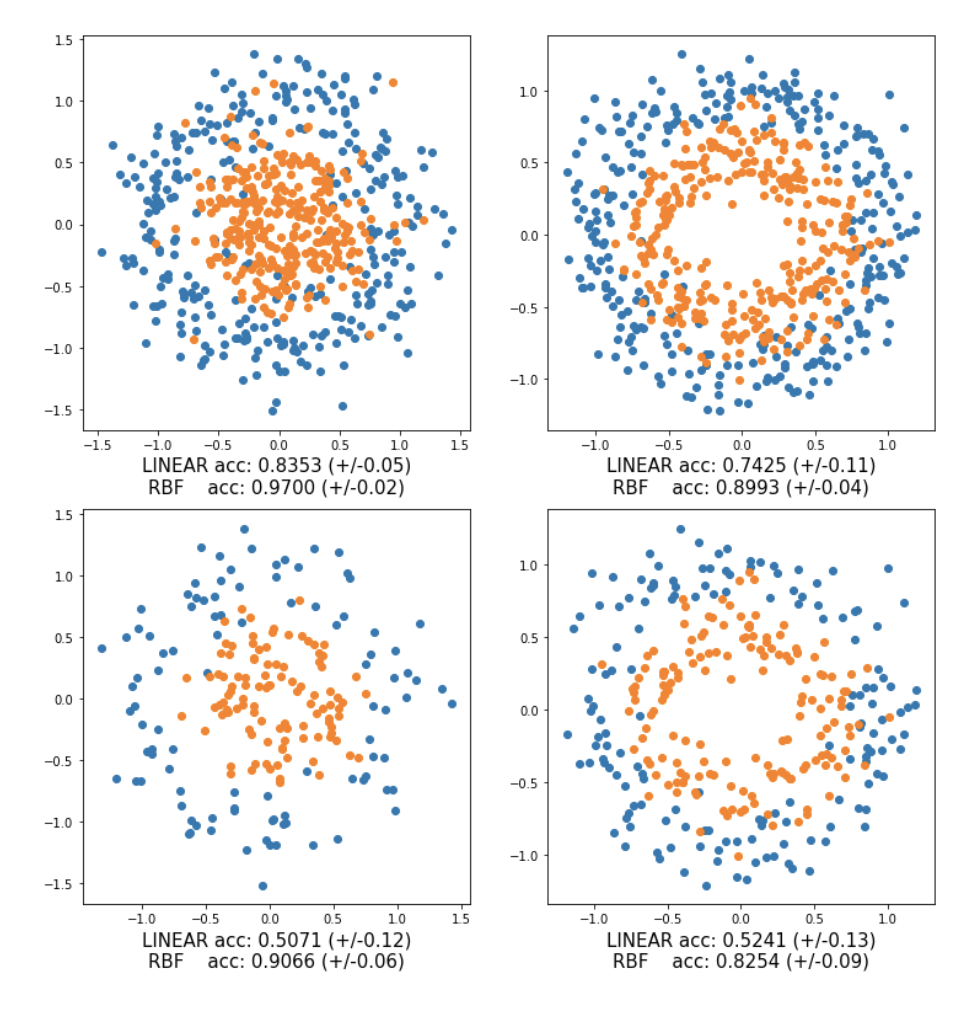
And this comes from synthetic data experiments, the dataset consists of two-dimensional data, arranged in concentric circles (top of the figure). As is evident, a linear function is inadequate for separating the two classes and it requires a more complex non-linear model such as a support vector machine (SVM) with a radial basis function (RBF) kernel. To simulate spurious correlations in the data, add class specific artificially constructed features (biases) sampled from two different Gaussian distributions.
The bias features make the task solvable through a linear function. Furthermore, for the first dataset, with the largest separation, flipped the labels of some biased samples, making the data slightly adversarial even to the RBF.
Once apply AFLITE, as expected, the number of biased samples is reduced considerably (bottom of the figure), making the task hard once again for the linear model, but still solvable for the nonlinear one.