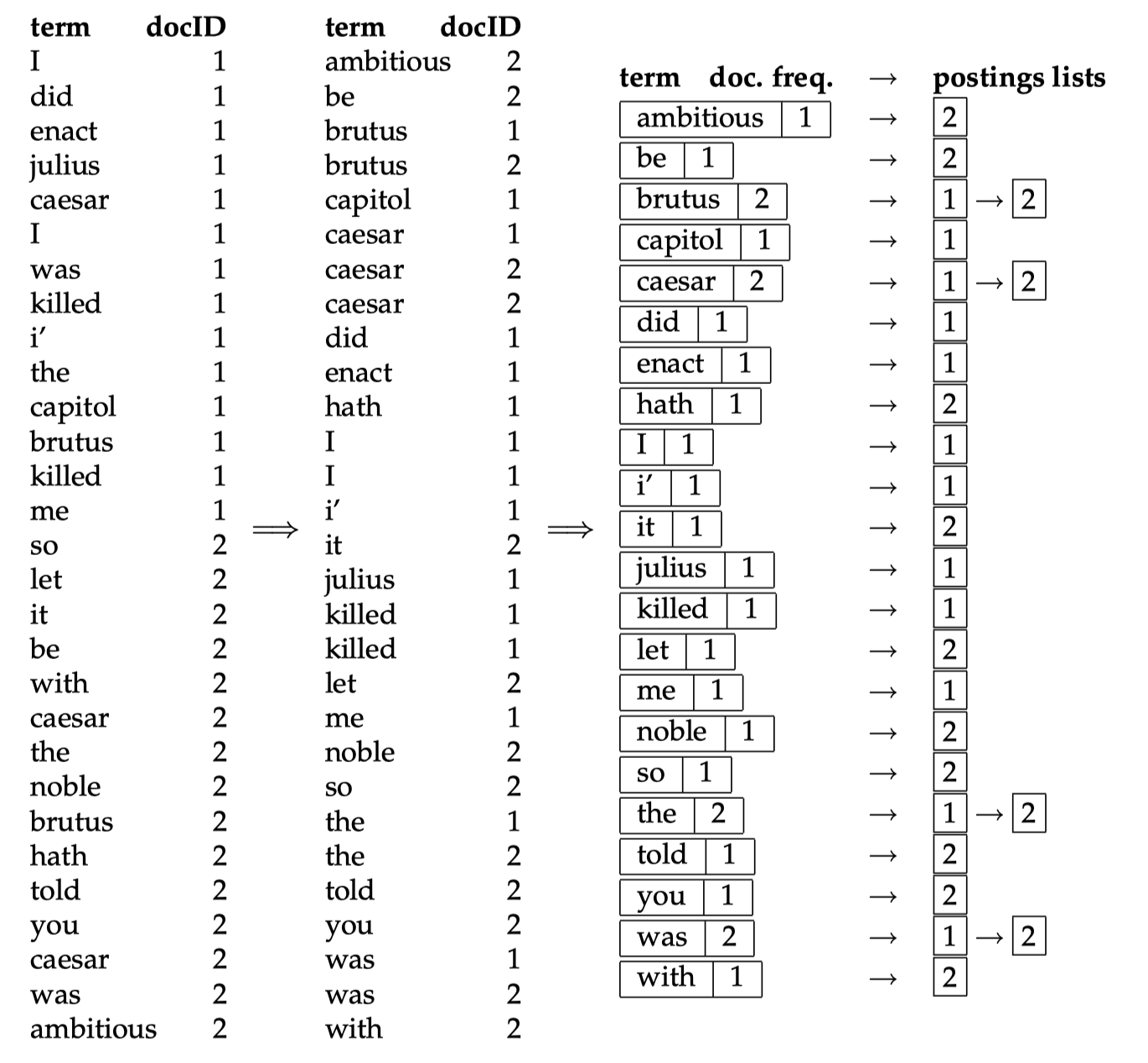
This is a general overview of index construction, from term ID, document ID pairs to final reversed index. To search a query, simply get all the document IDs which contain all the terms in the query and return to user.
Before going directly to index construction, we’ll talk about hardware basics first.
Access to data in memory (5 × 10 −9 seconds) is much faster than access to data on disk (2 × 10 −8 seconds).
So we want to keep as much data as possible in memory, especially those data that we need to access frequently. We call the technique of keeping frequently used disk data in main memory caching.
Operating systems generally read and write entire blocks.
Thus, reading a single byte from disk can take as much time as reading the entire block. We call the part of main memory where a block being read or written is stored a buffer.
Servers used in IR systems typically have several gigabytes (GB) of main memory, sometimes tens of GB. Available disk space is several orders of magnitude larger.
Blocked Sort-based Indexing (BSBI)
The algorithm parses documents into termID–docID pairs and accumulates the pairs in memory until a block of a fixed size is full. We choose the block size to fit comfortably into memory to permit a fast in-memory sort.
- segments the collection into parts of equal size
- sorts the termID–docID pairs of each part in memory
- stores intermediate sorted results on disk
- merges all intermediate results into the final index
The code below is only an illustraction, you can find my original code here.
First make a pass through the collection assembling all term–docID pairs.
td_pairs = []
for doc in doc_list:
doc_id = doc_map_dict.get(doc)
for term in doc:
term_id = term_map_dict.get(term)
td_pairs.append([term_id, doc_id])
Next, we sort the termID–docID pairs and collect all termID–docID pairs with the same termID into a postings list, where a posting is simply a docID.
td_dict = defaultdict(list)
for t, d in td_pairs:
td_dict[t].append(d)
for t in sorted(td_dict.keys()):
p_list = sorted(td_dict[t])
index.append(t, sorted(p_list))
The result, an inverted index for the block we have just read, is then written to disk. In the final step, the algorithm simultaneously merges all the blocks into one large merged index. To do the merging, we open all block files simultaneously, and maintain small read buffers for the ten blocks we are reading and a write buffer for the final merged index we are writing. In each iteration, we select the lowest termID that has not been processed yet using a priority queue or a similar data structure. All postings lists for this termID are read and merged, and the merged list is written back to disk.
last_term = last_posting = None
for curr_term, curr_postings in heapq.merge(*indices):
if curr_term != last_term:
if last_term:
last_posting = list(sorted(set(last_posting)))
merged_index.append(last_term, last_posting)
last_term = curr_term
last_posting = curr_postings
else:
last_posting += curr_postings
if last_term:
last_posting = list(sorted(set(last_posting)))
merged_index.append(last_term, last_posting)
Single-pass In-memory Indexing (SPIMI)
# only for illustration
dic = {}
for token, docId in stream:
if token not in dic:
dic[token] = []
dic[token] += [docId]
if no_memory:
write_to_file(sorted(dic))
Blocked sort-based indexing needs a data structure for mapping terms to termIDs. For very large collections, this data structure does not fit into memory. SPIMI uses terms instead of termIDs, writes each block’s dictionary to disk, and then starts a new dictionary for the next block. This does not need to maintain term-termID mapping across blocks.
A difference between BSBI and SPIMI is that SPIMI adds a posting directly to its postings list. Instead of first collecting all termID–docID pairs and then sorting them (as we did in BSBI), each postings list is dynamic (i.e., its size is adjusted as it grows) and it is immediately available to collect postings.
This has two advantages: It is faster because there is no sorting required, and it saves memory because we keep track of the term a postings list belongs to, so the termIDs of postings need not be stored. As a result, the blocks that individual calls of SPIMI can process are much larger and the index construction process as a whole is more efficient.
When memory has been exhausted, we write the index of the block (which consists of the dictionary and the postings lists) to disk. We have to sort the terms before doing this because we want to write postings lists in lexicographic order to facilitate the final merging step.
Distributed Indexing
Collections are often so large that we cannot perform index construction efficiently on a single machine. The result of the construction process is a distributed index that is partitioned across several machines – either according to term or according to document. Most large search engines prefer a document-partitioned index.
MapReduce is designed for large computer clusters, it’s a general architecture for distributed computing. The map and reduce phases of MapReduce split up the computing job into chunks that standard machines can process in a short time.
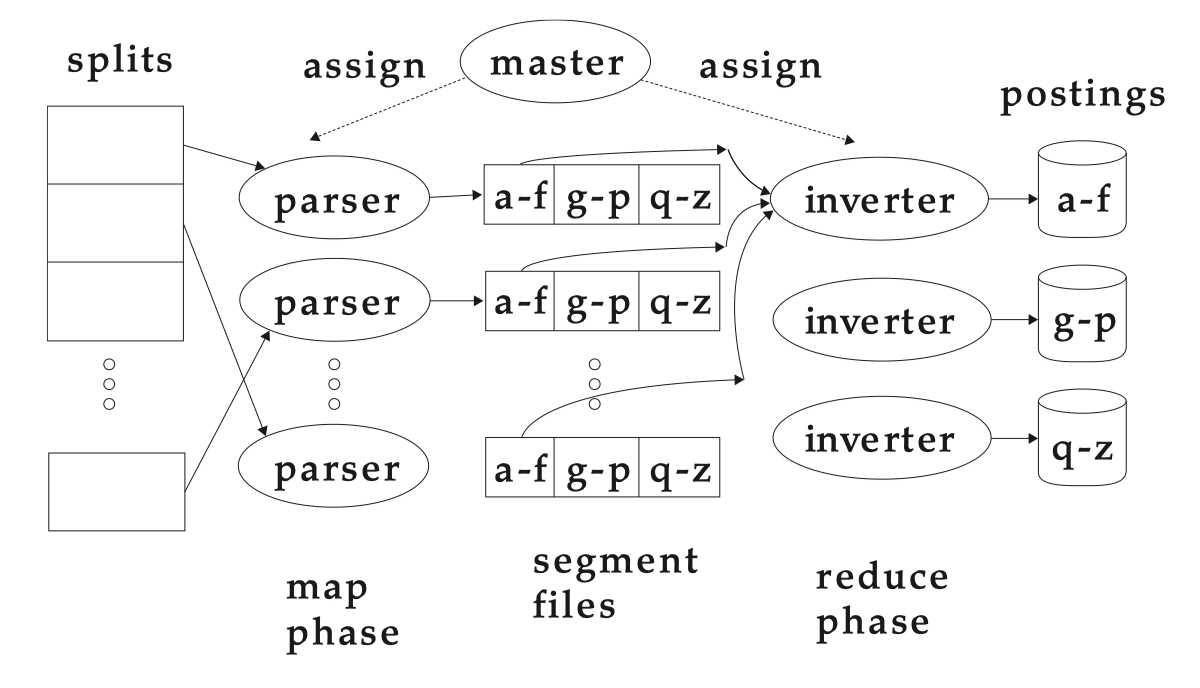
MapReduce breaks a large computing problem into smaller parts by recasting it in terms of manipulation of key-value pairs, like (termID,docID). We maintain a master machine directing the indexing job, assigns each task to an idle machine from a pool. And we will use two sets of parallel tasks, parsers and inverters.
Parser reads a document at a time and emits (term, doc) pairs, this is the same parsing task we also encountered in BSBI and SPIMI, then writes pairs into j partitions. An inverter collects all (term,doc) pairs for one term-partition, sorts and writes to postings lists.
Dynamic Indexing
In real world, most collections are modified frequently with documents being added, deleted, and updated. This means that new terms need to be added to the dictionary, and postings lists need to be updated for existing terms.
If there is a requirement that new documents be included quickly, one solution is to maintain two indexes: a large main index and a small auxiliary index that stores new documents.
The auxiliary index is kept in memory. Searches are run across both indexes and results merged. Deletions are stored in an invalidation bit vector. We can then filter out deleted documents before returning the search result. Documents are updated by deleting and reinserting them. Each time the auxiliary index becomes too large, we merge it into the main index.
Merging of the auxiliary index into the main index is efficient if we keep a separate file for each postings list, but then we would need a lot of files, that is inefficient for OS.
The simplest alternative is to store the index as one large file, that is, as a concatenation of all postings lists. In reality, we often choose a compromise between the two extremes.