Task Specification
In this post I’m going to implement a bidirectional LSTM model with CRF layer on top to tackle the NER task. Unlike in English where every word is naturally separated by a space, entities in Chinese text are not so straight forward: the boundaries between characters and words are not very clear, and word segmentation itself is a critical task in Chinese NLP. To avoid the extra segmentation, I treat it as a sequence labeling task, which means the model shold output a lable given one character.
Dataset Overview
The dataset is from Github, and the format is in IOB2(short for Inside, Outside, Beginning and the B- tag is used in the beginning of every chunk):
5/O 月/O 3/O 0/O 日/O 在/O 中/B-LOC 国/I-LOC 革/I-LOC 命/I-LOC 军/I-LOC 事/I-LOC 博/I-LOC 物/I-LOC 馆/I-LOC 开/O 幕/O 的/O 全/O 国/O 禁/O 毒/O 展/O 览/O ,/O 在/O 社/O 会/O 上/O 引/O 起/O 了/O 强/O 烈/O 的/O 反/O 响/O 。/O
Data Preprocess
The dataset itself is in high quality and requires no additional data cleaning.
We can simply read the data and store it in 2 list:
['2', '、', '国', '家', '林', '业', '局', '副', '局', '长', '李', '育', '才', '只', '能', '通', '过', '卫', '星', '电', '话', '协', '调', '云', '南', '空', '运', '洒', '水', '外', '挂', '件', '。'] # one element in sentence_list
['O', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'O', 'O', 'O', 'B-PER', 'I-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'] # one element in sentence_tag_list
Build Dictionary
After reading the dataset, it’s easy to build a dictionary with set():
char_set = set([char for sent in sentence_list for char in sent])
id_char_dict = {(idx+2): elem[0] for idx, elem in enumerate(char_set)}
id_char_dict[0] = "<PAD>" # special token for padding
id_char_dict[1] = "<UNK>" # special token for unknown(not in the dictionary)
char_id_dict = {v: k for k, v in id_char_dict.items()}
# tag_set is {'B-LOC', 'B-ORG', 'B-PER', 'I-LOC', 'I-ORG', 'I-PER', 'O'}
id_tag_dict = {idx: v for idx, v in enumerate(sorted( list(tag_set) )[::-1])}
# make sure index 0 is 'O'
tag_id_dict = {v: k for k, v in id_tag_dict.items()}
Convert sentence and tag to index
With the dictionary, convert sentences and tag sequences to their corresponding index.
Pad the Sequence
The sequence length should be fixed when being fitted into the model.
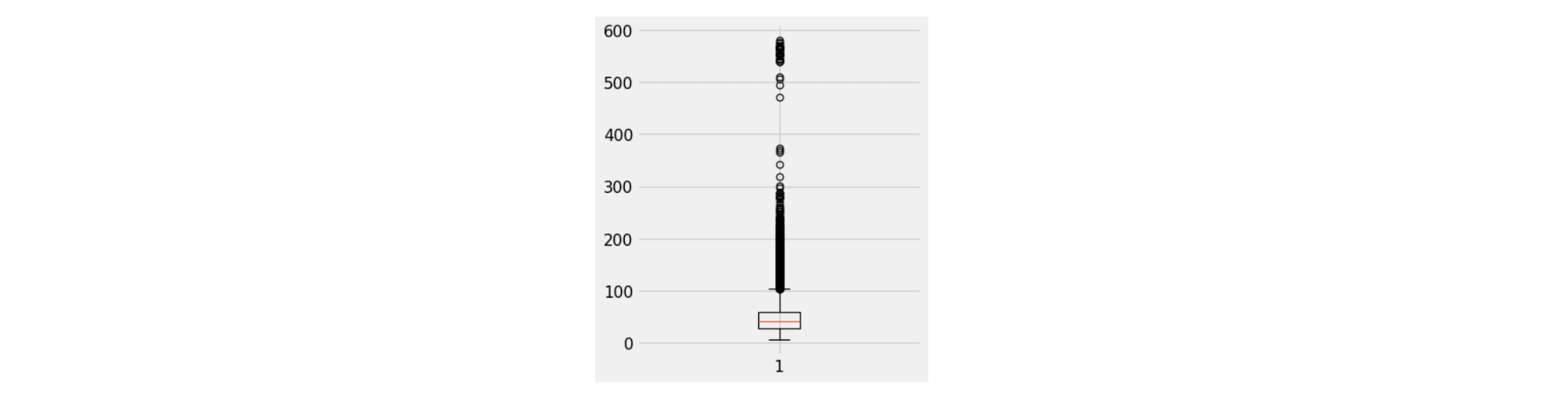 After analysis the sentence length, I set the sequence to 80, which satisfy 90% of the sentence length. All the sentences will be padded to the same length which is 80 and the oversized sentences will be truncated.
After analysis the sentence length, I set the sequence to 80, which satisfy 90% of the sentence length. All the sentences will be padded to the same length which is 80 and the oversized sentences will be truncated.
keras.preprocessing.sequence.pad_sequences() is a easy way to do this.
X = pad_sequences(sentence_encoded_list, maxlen=SEQUENCE_LEN)
# After the process, sentences should be like this
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 154, 619, 448,
45, 247, 830, 476, 1, 422, 185, 445, 765, 44, 63,
168, 40, 0, 118, 159, 496, 3, 1976, 220, 44, 303,
46, 4, 137, 98, 12, 294, 639, 418, 547, 1, 236,
726, 295, 789, 2, 163, 33, 76, 1147, 726, 2190, 15,
154, 645, 875], dtype=int32)
One-Hot Encode the Label
Keras has one util function called keras.utils.to_categorical()
y = to_categorical( pad_sequences(tag_encoded_list, maxlen=SEQUENCE_LEN), N_TAGS)
Build the Model
It’s super easy to build a neural network with Keras.
from keras.models import Model, Input
from keras.layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_accuracy
input = Input(shape=(SEQUENCE_LEN,))
embedding = Embedding(VOCAB_SIZE, EMBED_SIZE)(input)
lstm = Bidirectional(LSTM(units=50, return_sequences=True,
recurrent_dropout=0.1))(embedding)
dense = TimeDistributed(Dense(50, activation="relu"))(lstm)
crf = CRF(N_TAGS)
out = crf(dense)
model = Model(input, out)
model.compile(optimizer="rmsprop", loss=crf_loss, metrics=[crf_accuracy])
Train
X.shape # (None, 80)
y.shape # (None, 80, 7)
model.fit(x=X, y=y, batch_size=64, epochs=10)
Evaluation
Well, it only took 5 minutes to train this model on my laptop, so the result is not good. But we can still get some prediction on some text.
1997年11月1日
( [新华社](ORG) [北京](LOC) 11月1日电)
[江](PER) 主席离开 [纽约](LOC) 抵波士顿
在 [哈佛大学](ORG) 发表重要演讲在 [纽约](LOC) 时出席大型晚宴并演讲
本报 [波士顿](LOC) 11月1日电记者 [陈特安](PER) 、 [李云飞](PER) 报道: [江泽民](PER) 主席一行今天上午乘专机从 [纽约](LOC) 抵达 [波士顿](LOC) 访问。
数百名 [华](LOC) 人、 [华](LOC) 侨、留学人员、我国驻 [纽约总领事馆](ORG) 代表在机场挥舞 [中](LOC) [美](LOC) 两国国旗,热烈欢迎 [江](PER) 主席访问 [波士顿](LOC) 。
到机场迎接 [江](PER) 主席的 [美](LOC) 方人员有 [马萨](PER) 诸 [塞州州](LOC) 长和 [波士顿](LOC) 市长等。
陪 [同江主](PER) 席 [访问的国](ORG) 务院副 [总理兼](PER) 外交部长钱 [其琛和](PER) 夫 [人、](LOC) 特 [别](LOC) 助理 [曾庆红](PER) 、 [国务院](ORG) 外办主 [任刘华](PER) 秋 [、国家计](ORG) 委副主 [任曾培](PER) 炎 [、特别](ORG) 助理滕文 [生、中](PER) 国驻美大使李道豫、外交部副部长
又讯 [中国](LOC) 国家主席 [江泽民](PER) 1日上午应邀在 [美国](LOC) 著名学府 [哈佛大学](ORG) 发表重要演讲。
这是 [中国](LOC) 领导人首次在 [哈佛大学](ORG) 发表演讲。
Code is here.
Reference
Lample, Guillaume, et al. “Neural architectures for named entity recognition.” arXiv preprint arXiv:1603.01360 (2016).
Sequence Tagging With A LSTM-CRF
seqeval package on Github