Brief Definition
Latent Dirichlet Allocation(LDA) is a generative probabilistic model, a three-level hierarchical Bayesian model.
In the model, each item of a collection is modeled as a finite mixture over an underlying set of topics. And each topic is modeled as an infinite mixture over an underlying set of topic probabilities.
Process Overview
LDA assumes the following generative process for each document w in a corpus D:
- Choose N ∼ Poisson(ξ).
- Chooseθ ∼ Dir(α).
- For each of the N words wn:
(a) Choose a topic zn ∼ Multinomial(θ).
(b) Choose a word wn from p(wn |zn, β), a multinomial probability conditioned on the topic zn.
Start from Document Modeling
A document can be regarded as a sequence of words. Suppose I have a collection of documents generated with several predefined topics, and LDA’s task is guessing which the topics are by assigning probabilities of topics over a document and probabilities of words over a topic.
For example, given the number of topics 3, in the document “Language is very interesting”, randomly assign a topic to each word:
| word | language | is | very | interesting |
|---|---|---|---|---|
| topic | 1 | 3 | 2 | 2 |
And we got the probabilities of topics over this document by counting:
| topic | 1 | 2 | 3 |
|---|---|---|---|
| count | 1 | 2 | 1 |
By going through all the documents, we can calculate the probabilities of words over a topic:
| word\topic | 1 | 2 | 3 |
|---|---|---|---|
| language | 14 | 3 | 6 |
| is | 10 | 45 | 27 |
| very | 4 | 9 | 2 |
| interesting | 8 | 17 | 5 |
| how | 19 | 43 | 24 |
| to | 54 | 21 | 42 |
| … | … | … | … |
Above is the initial step. In the next, rescan all the documents and reassign the words with calculated probabilities, try to find the “right” place for the word and the document. LDA will do this again and again until it converges. And the result can be represented by the last table above.
How to Calculate the Probabilities
Basically there are two possibilities: document -> topic and topic -> word.
The picture is a graphical model representation of LDA from the original paper:
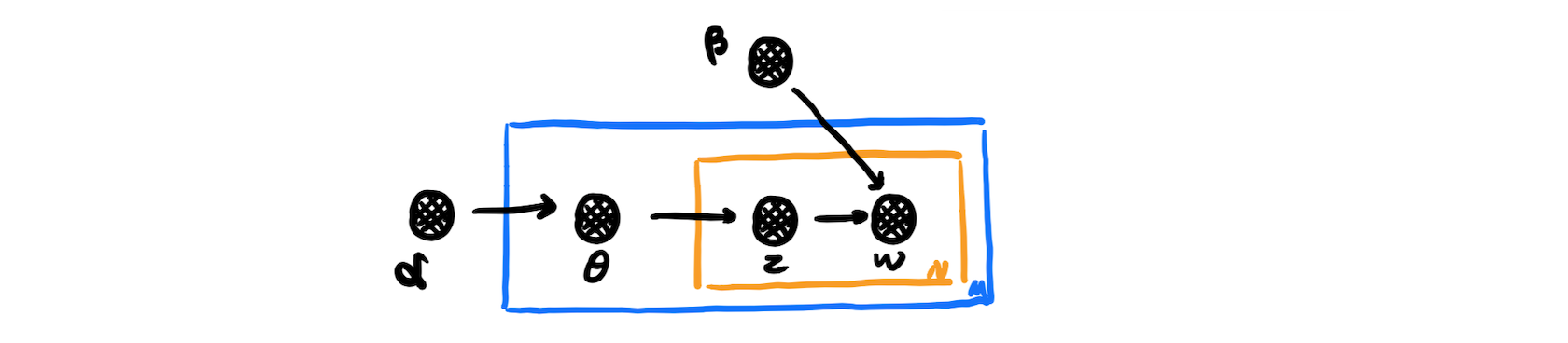
First let’s make it simpler.

In the yellow box, each document (in the range 0 -> M) is generated by first choosing a topic z and then generating N words independently from the conditional multinomial p(w|z).
And back to the graph representation, in the inner yellow box, instead of from the p(w|z), each word is from the distribution p(w|θ,β).
In the blue box, the topic (in the range 0 -> k) is picked by the multinomial p(z|θ), where θ is set by α.
The parameters α and β are corpus-level parameters, assumed to be sampled once in the process of generating a corpus. Apparently α is responsible for the document -> topic probability and β for the topic -> word probability.
To calculate the probabilities, LDA has to determine the parameters of those distribution. And they can be estimated by sampling from the corpus.
Why Dirichlet
In Bayesian probability theory, if the posterior distributions p(θ|x) are in the same probability distribution family as the prior probability distribution p(θ), the prior and posterior are then called conjugate distributions.
Dirichlet distribution is a conjugate distribution to the multinomial distribution.
The distributions of topic and word are multinomial, so we can use the observation to estimate the parameters in the Dirichlet distributions, which control the selection of topics and words. And as for the observation, Gibbs Sampling works.
Reference
Latent Dirichlet Allocation (original paper)
Latent Dirichlet Allocation (LDA) for Topic Modeling(Youtube)
Your Guide to Latent Dirichlet Allocation