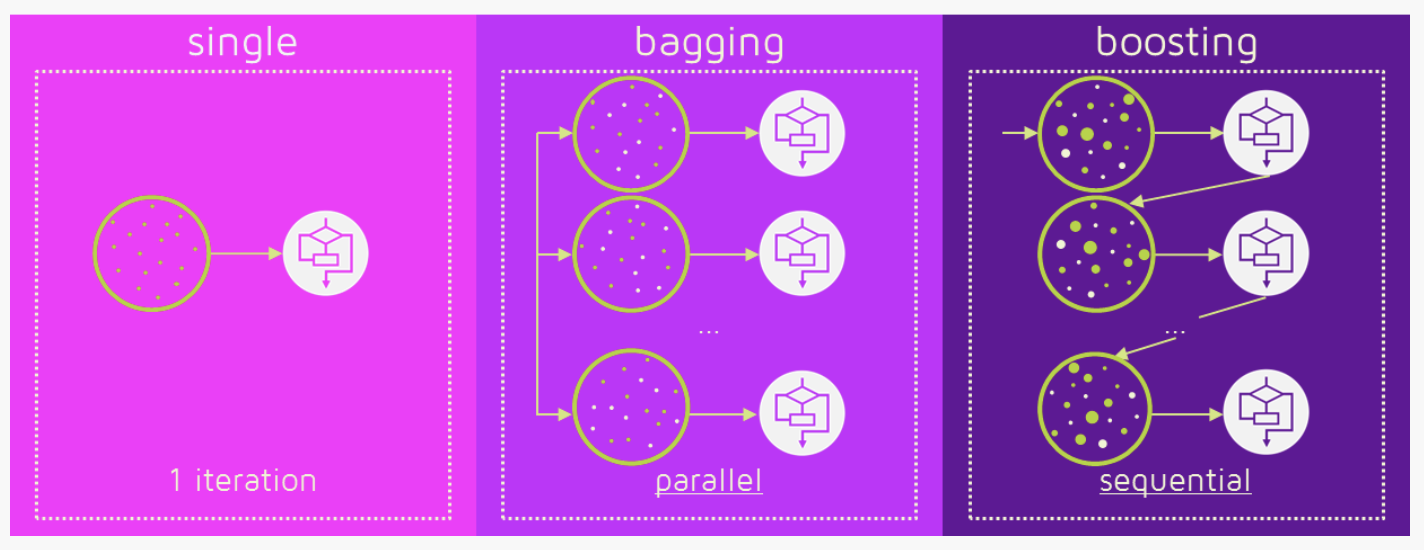
For a complex question, single classifier or predictor may give way to a multiple of them, an aggregated answer is always better, think about your life experience. And today, popular ensemble methods including bagging, boosting and stacking. Random Forest is also prevailing.
Voting Classifier
We start with the simple intuition, building a voting system over different classifiers, they could be Logistic Regression, SVM Classifier and Decision Tree… Then we count each classifier’s prediction and to get a overall prediction, it can be the majority vote, and this mechanism is call hard voting, or we can add a weight to each classifier, and obviously this is soft voting.
Bagging
Bagging is short for bootstrap aggregating, different from the previous voting classifier, where each classifier trained on the same training dataset, each classifier in bagging get a different training dataset, which is the subset of the training set using random sampling. When sampling is performed without replacement, it is call pasting.
AdaBoost
Suppose in the training process, we want to pay more attention to the classifier which performed bad before, and give those worse classifier less weights in the final prediction, then there’s a technique call AdaBoost. For m classifiers, we initialize the weight of each to \(\frac{1}{m}\), that is $$D_1 = (w_{11}, …, w_{1i}, …, w_{im}), \quad w_{1i} = \frac{1}{m}, \quad i = 1,2,…,m$$ And during the training process, we compute the error rate at every epoch, for the jth predictor or classifier, which is $$r_j = \frac{\sum_{i=1, \hat{y}^{(i)} \neq y^{(i)}}^{m} w^{(i)}}{\sum_{i=1}^{m} w^{(i)}}$$ \( \hat{y}^{(i)} \) is the current prediction for the ith instance Then we can get the weight of each classifier for the next step, $$\alpha_j = \eta log \frac{1 - r_j}{r_j}$$ the more accurate classifier will get higher weight.
And next we’re going to update the weights, for the wrong classifier, $$w^{(i)} = w^{(i)}exp(\alpha_j), \qquad if \quad \hat{y}^{(i)} \neq y^{(i)}$$ and the weight of correct classifier stays the same. Then all the weights got normalized, that is by dividing \(\sum_{i=1}^{m}w^{(i)}\)
Then in the prediction process, we compute the predictions of all the classifiers and weights them using the \(\alpha_j\), and the majority prediction is the final result.
Gradient Boosting
Unlike previous AdaBoost, gradient boosting fit the predictor to the residual errors made by previous predictor.
First, define the loss function, \(L(y,f(x))\), \(y\) is the label, \(f(x)\)is the model, eg. Regression Tree. 1. the initialization: $$f_0(x) = arg min_c \sum_{i = 1}^{n}L(y_i, c)$$ c is a constant 2. compute the residule $$r_{mi} = -[\frac{ \partial L(y,f(x_i))}{ \partial f(x_i)} ]_{f(x)=f_{m-1}(x)}$$ 3. train the model with the residule, eg. training set is \((x_i,r_{mi})\) 4. the optimization $$c_{m} = arg min_c \sum_{i=1}^{n}L(y_i, f_{m-1}(x_i) + ch_m(x_i))$$ 5. update $$f_m(x) = f_{m-1}(x) + c_m h_m (x)$$
Related blogs
Gradient Boosting from scratch comparison between bagging and boosting