Task Specification
In contract to classification, clustering is always considered as an unsupervised approach and usually applied to unlabeled data. Afterall most of the data in the world are unlabeled. Text clustering is a way to explore and group the text data for further analysis and can be applied to many tasks like document classification, organizaion, browsing etc..
General Steps Overview
- Text cleaning
- Text representation(feature engineering)
- Clustering algorithms
- Aanlysis of result
Text Cleaning
Most of the text data contains unwanted characters depending on the way we collect it, the first step is usually removing those interference. A lot of data is directly crawled from the web page, so in most cases html tags, special characters do not have positive contribution to the final result, and a filter is always applied to those data. Sometimes the text data is collected via user input, there can be typos, useless terms.
Here I removed characters which do not usually appear in Chinese documents with regular expression. The dataset is the same as in the text classification practice
def clean_data(text):
cleaned_text = re.sub(r"[\s\/\\_$^*(+\"\'+~\-@#&^*\[\]{}【】]+", "", str(text))
return cleaned_text
Text Representation
Raw text data cannot be fed into clustering algorithms directly, a representation of the text data is necessary. As I always do, I’ll use three different representations.
Bag of Words
# Build a dictionary
word_counter = Counter([x for y in select_data.words.tolist() for x in y])
id_word_dict = {idx: item[0] for idx, item in enumerate(word_counter.most_common())}
word_id_dict = {word: idx for idx, word in id_word_dict.items()}
# Convert word list to id list
def word_to_id(word_list):
return [word_id_dict[w] for w in word_list]
select_data['word_id'] = select_data.words.apply(word_to_id)
# Create a matrix for the feature
bow_encoding = np.zeros([len(select_data), len(id_word_dict)])
# Count the words and add to feature
for idx, words in enumerate(select_data.word_id.tolist()):
for w in words:
bow_encoding[idx][w] += 1
TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [' '.join(item) for item in select_data.words.tolist()]
tfidf = TfidfVectorizer()
tfidf_encoding = tfidf.fit_transform(corpus)
BERT
It’s a state of art model at this time, I take the second to last layer encoding in the model as a distributed representation of the sentence.
from bert_serving.client import BertClient
bc = BertClient()
bert_encoding = bc.encode(select_data.review.tolist())
Clustering Algorithm
There are several ways to perform clustering, K-Means, DBSCAN, GMM… As an illustration I just start from K-Means.
# Start clustering
from sklearn.cluster import KMeans
N_clusters = 50 # set a number of clusters
bow_pred = KMeans(n_clusters=N_clusters, random_state=0).fit_predict(bow_encoding)
Analysis
I printed some clustering distribution below.
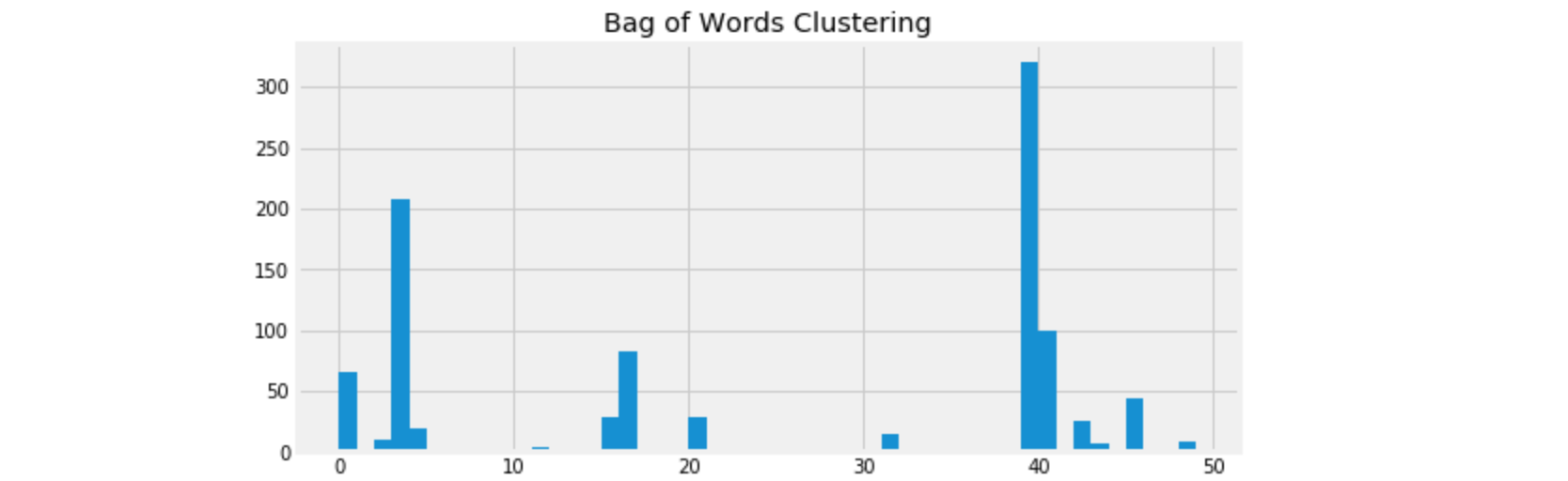 To make it more clear, I set the number of clusters up to fifty, and the distribution is very uneven. The way of bag of words representation is very primitive and take that every word is equal important. Therefore in the clustering process some stop words may be the clue or keywords of some cluster, this makes no sense to us.
To make it more clear, I set the number of clusters up to fifty, and the distribution is very uneven. The way of bag of words representation is very primitive and take that every word is equal important. Therefore in the clustering process some stop words may be the clue or keywords of some cluster, this makes no sense to us.
 For example in this case, the sentences actually have no similarity, but the character ‘、’ serves as the key of the cluster.
But this representation also have some benefits, it’s quick to compute, and if there really are some obvious keywords, bag of words representation can be an efficient way to find them.
For example in this case, the sentences actually have no similarity, but the character ‘、’ serves as the key of the cluster.
But this representation also have some benefits, it’s quick to compute, and if there really are some obvious keywords, bag of words representation can be an efficient way to find them.
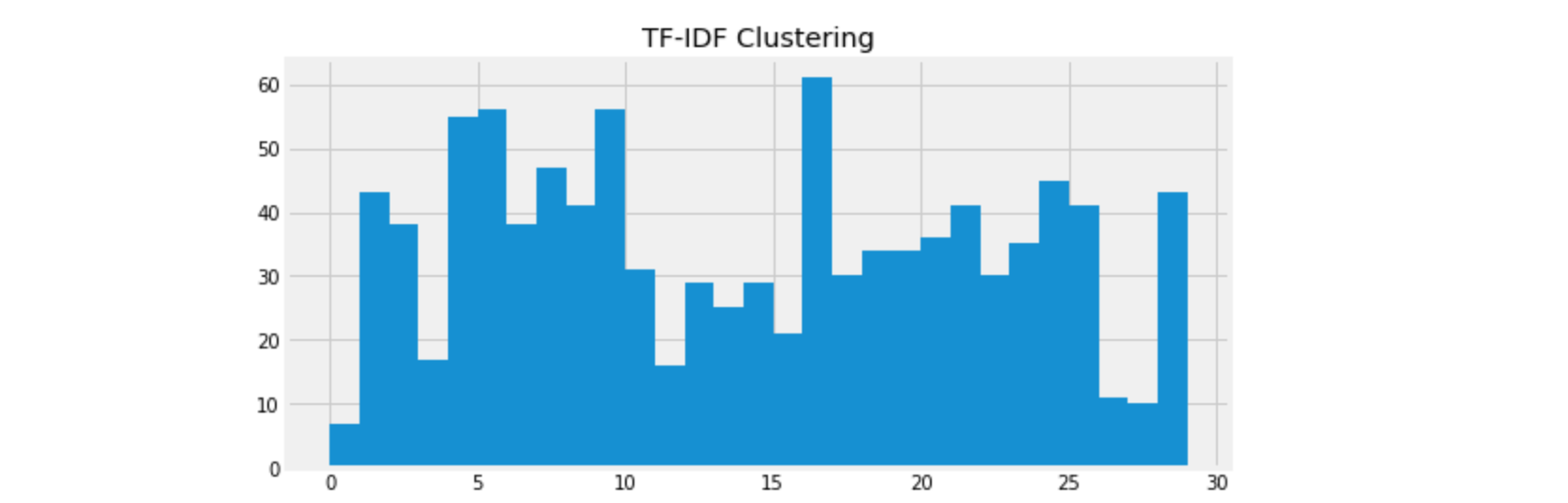 TF-IDF is a way to indicate the relative importance of different words in the corpus. And we can see it’s more balanced than the previous bag of words one. Compared to bag of words, TF-IDF assigns a score to each word and extremely low score words can be filtered at this time. So it’s a more stable way to represent text data.
TF-IDF is a way to indicate the relative importance of different words in the corpus. And we can see it’s more balanced than the previous bag of words one. Compared to bag of words, TF-IDF assigns a score to each word and extremely low score words can be filtered at this time. So it’s a more stable way to represent text data.
 It is obviously in this cluster every review has the words ‘赠品’(gift)
It is obviously in this cluster every review has the words ‘赠品’(gift)
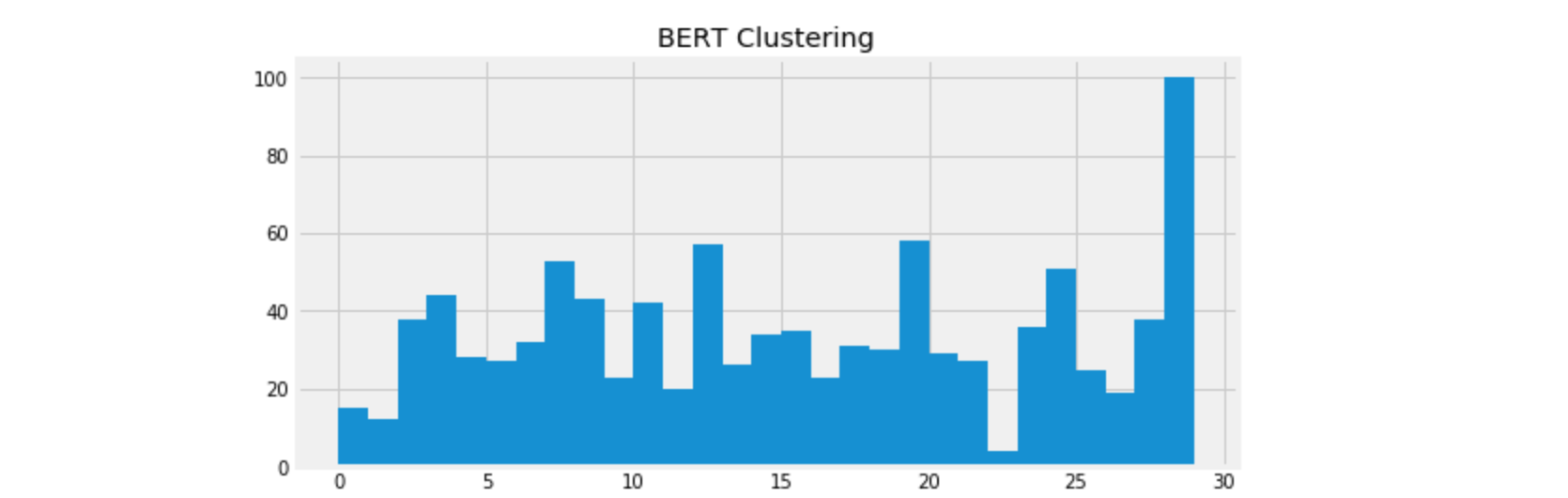
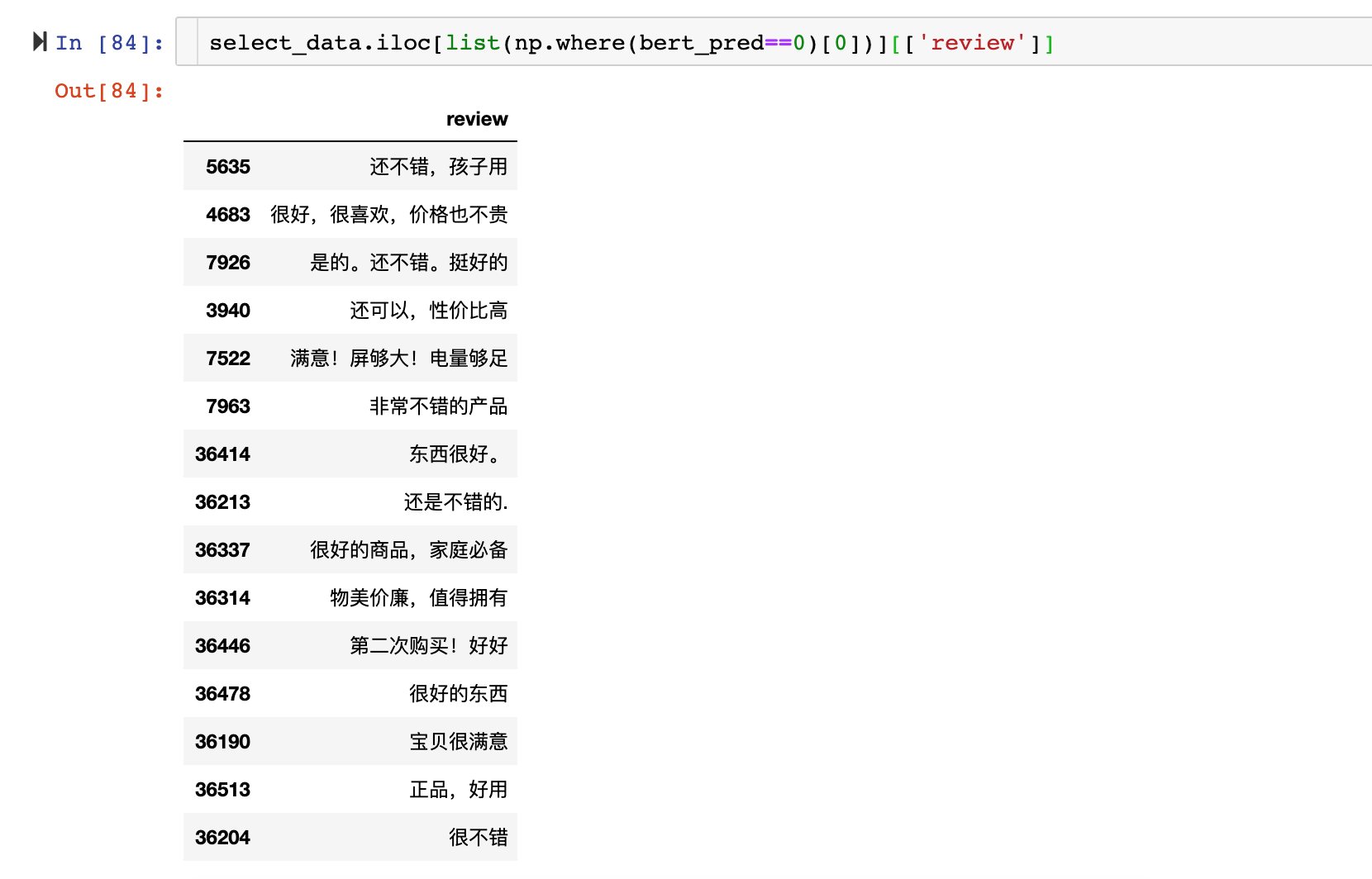 Word vectors have a very good reputation in representation today. Though the distribution seems like the TF-IDF one, the result makes much more sense. We can see from the example, these sentences indeed have high similarity.
Word vectors have a very good reputation in representation today. Though the distribution seems like the TF-IDF one, the result makes much more sense. We can see from the example, these sentences indeed have high similarity.
Since the clustering algorithm works on vectors, a key question is how to represent the text data. We human are able to do this because we have prior knowledge of those words, we’ve known the meaning. But to machine, there is no semantical difference between words except we provided in the representation, just like the BERT encoding did.
By tuning the parameters of clustering algoritms and analyzing the final clusters, we can explore text data in a more efficient and intuitive way, and this is what I usually do when I got a new dataset.
You can find my code here.